이 논문이 소개되고 얼마 되지 않아 Toxic 컴페티션에 개최돼서 많은 참가자가 BERT 학습을 위해 애를 썼습니다. 실제로 메달권에 들어가기 위해서는 BERT를 무조건 사용해야 했을 정도로 엄청난 성능을 자랑했습니다.
BERT 모델이 엄청난 성능을 낼 수 있었던 이유는 Word2Vec이나 Glove 같은 단어 수준 임베딩을 넘어서 트랜스포머 인코더 구조를 활용한 문장 수준의 임베딩을 사용했기 때문입니다. 문장 수준 임베딩에서는 문장의 문맥을 고려하여 같은 단어라 할지라도 속한 문장에 따라 다른 의미를 가질 수 있도록 학습이 가능합니다. 따라서 BERT는 앞서 Overview에서 언급한 Unintended Bias를 줄여야 하는 이 대회의 주제를 잘 풀어낼 수 있는 잠재력을 가지고 있는 모델입니다.
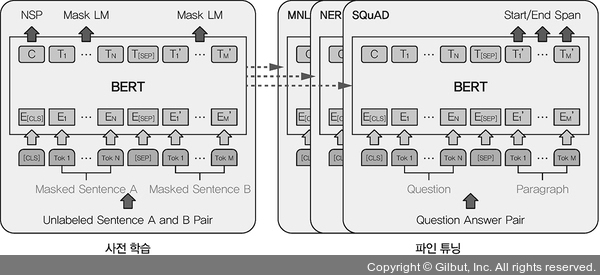
▲ 그림 7-10 BERT 구조도