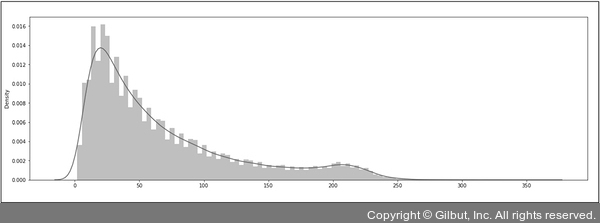
▲ 그림 7-11 토큰화한 텍스트의 길이 통계량
Note ≣ | 텍스트 시퀀스 데이터 구성 방법
모델 학습을 위한 텍스트 시퀀스(Sequence) 데이터를 구성하는 방법은 크게 두 가지입니다.
1. 모든 텍스트 토큰 데이터를 고정된 길이(MAX_LEN)로 통일한다.
2. 텍스트 토큰 데이터를 가변적으로 설정해두고 딥러닝 학습 시 각 배치(Batch)마다 같은 길이를 가지도록 처리 로직을 추가한다.
1번은 별다른 로직을 추가하지 않고도 할 수 있는 가장 간단한 방법입니다. 하지만 이 방법의 가장 큰 단점은 무의미한 패딩 토큰이 많아져 계산 효율을 떨어트릴 수 있다는 것입니다. 특히 텍스트 데이터 같이 토큰 길이가 매우 다양할 수 있는 데이터라면 더욱 영향이 큽니다.