쪼개진 단어들은 모두 glove_embeddings 딕셔너리에 포함되어 있습니다. 전처리에 이를 적용한 후 다시 커버리지를 구하면 그림 7-22와 같이 나타납니다. 이전과 비교했을 때, 중복을 제외한 단어 집합이 43.30%로 상승했습니다. 이후 oov 형태를 참고해서 필요한 전처리를 추가해가면 됩니다. 이처럼 적절한 전처리를 적용하여 사용할 임베딩 모델이 주어진 텍스트를 최대한 많이 커버할수록 입력 텍스트의 정보의 손실을 줄일 수 있습니다.
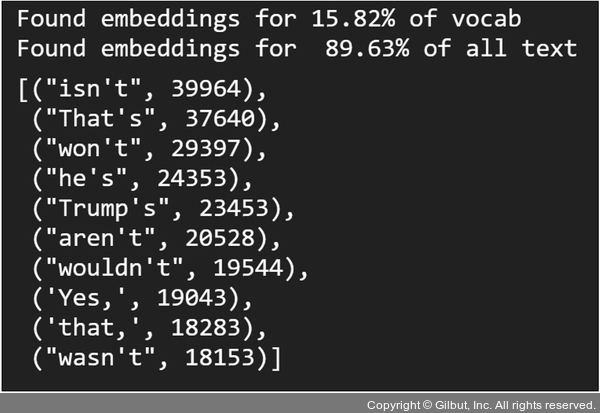
▲ 그림 7-21 사전 학습 워드 임베딩의 텍스트 커버리지(전처리 적용 전)
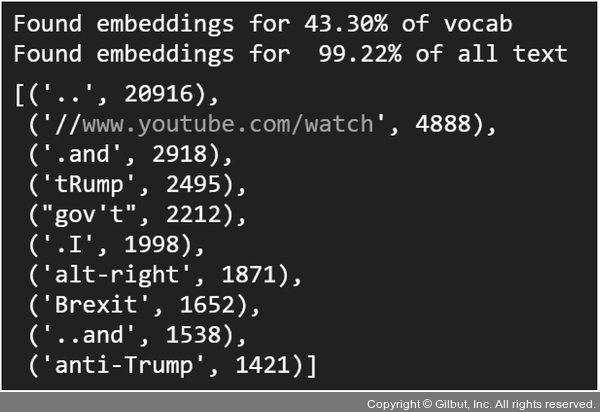
▲ 그림 7-22 축약어 형태를 전처리한 후 텍스트 커버리지