지도 학습 방식으로 영상을 인식하는 과정을 그림 15-1에 나타냈습니다. 영상 데이터는 픽셀로 구성되어 있지만, 이 픽셀 값을 그대로 머신 러닝 입력으로 사용하는 것은 그다지 흔치 않습니다. 왜냐하면 영상의 픽셀 값은 조명 변화, 객체의 이동 및 회전 등에 의해 매우 민감하게 변화하기 때문입니다. 그러므로 많은 머신 러닝 응용에서는 영상의 다양한 변환에도 크게 변경되지 않는 특징 정보를 추출하여 머신 러닝 입력으로 전달합니다. 사과와 바나나 사진을 구분하는 용도라면 영상의 주된 색상(hue) 또는 객체 외곽선과 면적 비율 등이 유효한 특징으로 사용될 수 있습니다. 이처럼 영상 데이터를 사용하는 지도 학습에서는 먼저 다수의 훈련 영상에서 특징 벡터를 추출하고, 이를 이용하여 머신 러닝 알고리즘을 학습시킵니다. 학습의 결과로 생성된 학습 모델은 이후 예측 과정에서 사용됩니다. 예측 과정에서도 입력 영상으로부터 특징 벡터를 추출하고, 이 특징 벡터를 학습 모델 입력으로 전달하면 입력 영상이 어떤 영상인지에 대한 예측 결과를 얻을 수 있습니다.
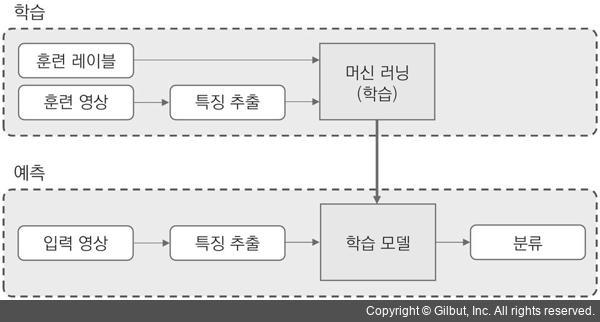
▲ 그림 15-1 지도 학습에 의한 영상 분류 과정