머신 러닝 알고리즘 종류에 따라서는 내부적으로 사용하는 많은 파라미터에 의해 성능이 달라지기도 합니다. 그러므로 최적의 파라미터를 찾는 것이 또 하나의 해결해야 할 문제가 되기도 합니다. 이런 경우에는 훈련 데이터를 k개의 부분 집합으로 분할하여 학습과 검증(validation)을 반복하면서 최적의 파라미터를 찾을 수도 있습니다. 예를 들어 8000개의 훈련 영상을 800개씩 열 개의 부분 집합으로 분할하고, 이 중 아홉 개의 부분 집합으로 학습하고 나머지 한 개의 집합을 이용하여 성능을 검증합니다. 그리고 검증을 위한 부분 집합을 바꿔 가면서 여러 번 학습과 검증을 수행합니다. 이러한 작업을 다양한 파라미터에 대해 수행하면서 가장 성능이 높게 나타나는 파라미터를 찾을 수 있습니다. 이처럼 훈련 데이터를 k개의 부분 집합으로 분할하여 학습과 검증을 반복하는 작업을 k-폴드 교차 검증(k-fold cross-validation)이라고 합니다.
머신 러닝 알고리즘으로 훈련 데이터를 학습할 경우 훈련 데이터에 포함된 잡음 또는 이상치(outlier)의 영향을 고려해야 합니다. 많은 머신 러닝 분류 알고리즘이 훈련 데이터를 효과적으로 구분하는 경계면을 찾으려고 합니다. 그런데 만약 훈련 데이터에 잘못된 정보가 섞여 있다면 경계면을 어떻게 설정하는 것이 좋은지 모호해질 수 있습니다. 그림 15-2는 빨간색 삼각형과 파란색 사각형 점을 구분하는 분류 문제입니다. 두 가지 종류의 점을 완벽하게 구분하는 경계면은 분명 보라색 점선입니다. 그러나 보라색 경계면은 훈련 데이터에 대해서는 100% 정확하게 동작하지만 실제 새로운 입력 데이터에 대해서는 오히려 정확도가 떨어질 수 있는 가능성을 포함하게 됩니다. a와 b 점은 각각 빨간색 삼각형과 파란색 사각형 분포와 동떨어진 위치에 존재하기 때문에 잡음 또는 잘못 측정된 이상치일 가능성이 높기 때문입니다. 이때는 보라색 점선 경계면보다는 오히려 녹색 실선 경계면을 사용하는 것이 실제 테스트에서 더 좋은 성능을 보여 줄 수 있습니다.
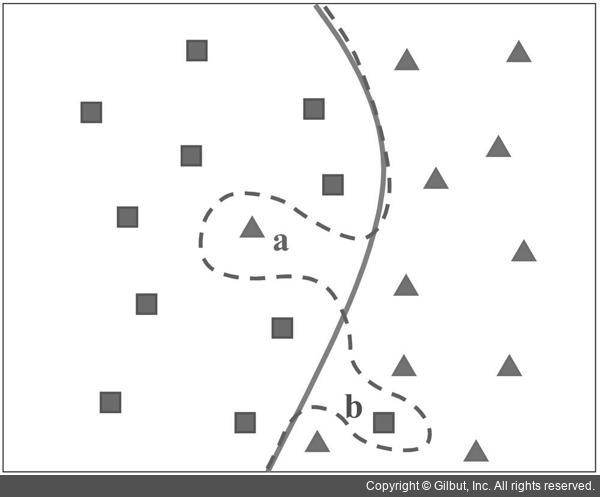
▲ 그림 15-2 훈련 데이터에 이상치가 있을 경우의 분류 경계면