그러나 그림 15-4를 좀 더 관찰해 보면 녹색 점 주변에 빨간색 삼각형보다 파란색 사각형이 더 많이 분포하는 것을 알 수 있습니다. 실제로 녹색 점을 중심으로 하는 원을 보라색 실선으로 그려 보면 원 안에 빨간색 삼각형보다 파란색 사각형이 더 많이 나타나는 것을 확인할 수 있습니다. 보라색 실선 원 안에 파란색 사각형은 두 개가 있고, 빨간색 삼각형은 하나만 존재합니다. 원을 조금 더 키워서 보라색 점선으로 그려진 원을 살펴보면 파란색 사각형이 세 개, 빨간색 삼각형이 두 개 발견됩니다. 즉, 녹색 점에서 가장 가까운 도형은 빨간색 삼각형이지만, 이 지점은 파란색 사각형이 더 많이 분포하는 지역이라고 판단할 수 있습니다. 그러므로 녹색 점을 파란색 사각형 클래스로 지정하는 것이 더욱 합리적일 수 있으며, 이러한 방식으로 분류하는 방법을 kNN 알고리즘이라고 합니다.
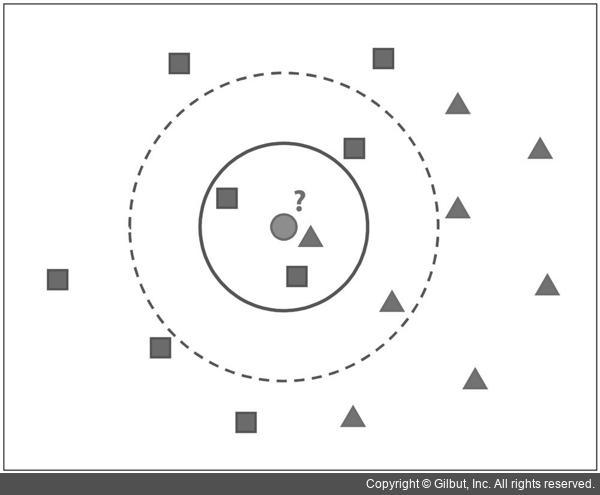
▲ 그림 15-4 kNN 알고리즘에 의한 점 분류
kNN 알고리즘에서 k를 1로 설정하면 최근접 이웃 알고리즘이 됩니다. 그러므로 보통 k는 1보다 큰 값으로 설정하며, k 값을 어떻게 설정하느냐에 따라 분류 및 회귀 결과가 달라질 수 있습니다. 최선의 k 값을 결정하는 것은 주어진 데이터에 의존적이며, 보통 k 값이 커질수록 잡음 또는 이상치 데이터의 영향이 감소합니다. 그러나 k 값이 어느 정도 이상으로 커질 경우 오히려 분류 및 회귀 성능이 떨어질 수 있습니다.