이처럼 기본적인 퍼셉트론은 입력 데이터를 두 개의 클래스로 선형 분류하는 용도로 사용할 수 있습니다. 좀 더 복잡한 형태로 분포되어 있는 데이터 집합에 대해서는 노드의 개수를 늘리거나, 입력과 출력 사이에 여러 개의 은닉층(hidden layer)을 추가하는 형태로 구조를 발전시켜 해결할 수 있습니다. 그림 16-4는 여러 개의 은닉층이 존재하는 다층 퍼셉트론(MLP, Multi-Layer Perceptron) 구조의 예입니다.
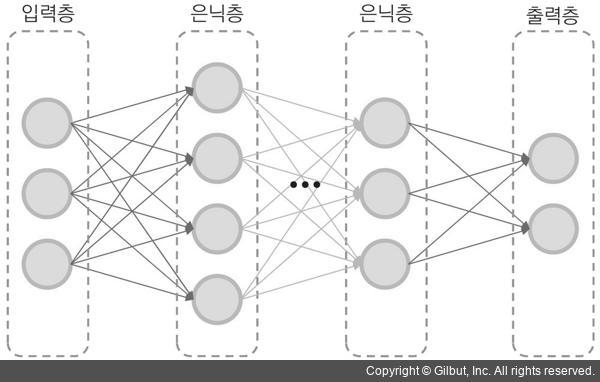
▲ 그림 16-4 다층 퍼셉트론
신경망이 주어진 문제를 제대로 해결하려면 신경망 구조가 문제에 적합해야 하고, 에지에 적절한 가중치가 부여되어야 합니다. 에지의 가중치와 편향 값은 경사 하강법(gradient descent), 오류 역전파(error backpropagation) 등의 알고리즘에 의해 자동으로 결정할 수 있습니다. 신경망에서 학습이란 결국 훈련 데이터셋을 이용하여 적절한 에지 가중치와 편향 값을 구하는 과정이라고 할 수 있습니다.
그러나 신경망은 2000년대 초반까지 크게 발전하지 못했습니다. 그 이유는 은닉층이 많아질수록 학습 시간이 너무 오래 걸리고, 학습도 제대로 되지 않는 문제가 해결되지 않았기 때문입니다. 그러다가 2000년대 후반, 2010년 초반부터 신경망은 심층 신경망 또는 딥러닝이라는 새로운 이름으로 크게 발전하기 시작했습니다. 2000년대에 딥러닝이 크게 발전한 이유는 크게 세 가지를 들 수 있습니다. 첫 번째는 딥러닝 알고리즘이 개선되면서 은닉층이 많아져도 학습이 제대로 이루어지게 되었다는 점입니다. 두 번째는 하드웨어의 발전, 특히 GPU(Graphics Processing Unit) 성능 향상과 GPU를 활용한 학습 방법으로 인해 딥러닝 학습 시간이 크게 단축되었기 때문입니다. 세 번째 이유는 인터넷의 발전에 따른 빅데이터 활용이 용이해졌다는 점입니다. 특히 컴퓨터 비전 분야에서는 Pascal VOC1, ImageNet2과 같이 잘 다듬어진 영상 데이터를 활용할 수 있었다는 점이 큰 장점으로 작용했습니다. 대용량 영상 데이터셋을 이용한 영상 인식 대회 등을 통해 알고리즘 경쟁과 공유가 활발하게 이루어졌다는 점도 딥러닝 발전에 긍정적인 영향을 끼쳤습니다.
1 2005년부터 2012년까지 진행되었던 영상 인식, 객체 검출, 분할 등의 성능을 겨루는 대회입니다. 이때 사용되었던 영상 데이터셋은 http://host.robots.ox.ac.uk/pascal/VOC/ 웹 사이트에서 내려받을 수 있습니다.
2 ImageNet은 사람이 수작업으로 분류한 1400만 개 이상의 영상 데이터셋입니다. 공식 사이트 주소는 http://www.image-net.org/입니다.