내려받은 학습 모델 파일은 2016년에 발표된 SSD(Single Shot Detector) 알고리즘을 이용하여 학습된 파일입니다[Liu16]. SSD는 입력 영상에서 특정 객체의 클래스와 위치, 크기 정보를 실시간으로 추출할 수 있는 객체 검출 딥러닝 알고리즘입니다. SSD 알고리즘은 원래 다수의 클래스 객체를 검출할 수 있지만 OpenCV에서 제공하는 얼굴 검출은 오직 얼굴 객체의 위치와 크기를 알아내도록 훈련된 학습 모델을 사용합니다.
기본적인 SSD 네트워크 구조를 그림 16-14에 나타냈습니다. 이 구조에서 입력은 300×300 크기의 2차원 BGR 컬러 영상을 사용합니다. 이 영상은 Scalar(104, 117, 123) 값을 이용하여 정규화한 후 사용합니다.12 SSD 네트워크의 출력은 추출된 객체의 ID, 신뢰도, 사각형 위치 등의 정보를 담고 있습니다. SSD 알고리즘에 대한 좀 더 자세한 설명은 [Liu16] 참고 문헌을 참고하기 바랍니다.
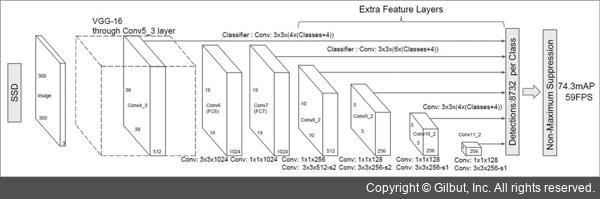
▲ 그림 16-14 SSD 네트워크 구조13
12 훈련 시 사용된 평균값 정보는 train.prototxt 파일을 참고하여 알 수 있습니다.
13 그림 출처: [Liu16]