SVM의 목적 함수는 샘플이 정확하게 분류된다는 제약 조건하에서 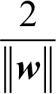 를 최대화함으로써 마진을 최대화하는 것입니다. 이 제약은 다음과 같이 쓸 수 있습니다.
를 최대화함으로써 마진을 최대화하는 것입니다. 이 제약은 다음과 같이 쓸 수 있습니다.
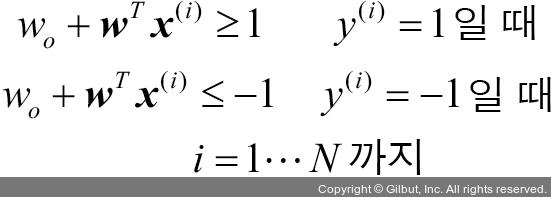
여기서 N은 데이터셋에 있는 샘플 개수입니다.
이 두 식이 말하는 것은 다음과 같습니다. 모든 음성 클래스 샘플은 음성 쪽 초평면 너머에 있어야 하고 양성 클래스 샘플은 양성 쪽 초평면 너머에 있어야 합니다. 이를 다음과 같이 간단히 쓸 수 있습니다.19
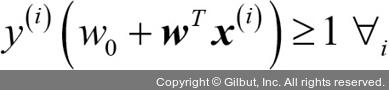
실제로는 동일한 효과를 내면서 콰드라틱 프로그래밍(quadratic programming) 방법으로 풀 수 있는 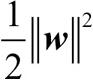 을 최소화하는 것이 더 쉽습니다. 콰드라틱 프로그래밍에 대한 자세한 설명은 책 범위를 넘어섭니다.20 서포트 벡터 머신에 대한 자세한 내용은 ‘ The Nature of Statistical Learning Theory, Springer Science+Business Media, Vladimir Vapnik, 2000 또는 A Tutorial on Support Vector Machines for Pattern Recognition(Data Mining and Knowledge Discovery, 2(2): 121-167, 1998)’을 참고하세요.
을 최소화하는 것이 더 쉽습니다. 콰드라틱 프로그래밍에 대한 자세한 설명은 책 범위를 넘어섭니다.20 서포트 벡터 머신에 대한 자세한 내용은 ‘ The Nature of Statistical Learning Theory, Springer Science+Business Media, Vladimir Vapnik, 2000 또는 A Tutorial on Support Vector Machines for Pattern Recognition(Data Mining and Knowledge Discovery, 2(2): 121-167, 1998)’을 참고하세요.
19 역주 전칭 기호 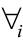 는 ‘모든 샘플에 대해서’라는 뜻입니다.
는 ‘모든 샘플에 대해서’라는 뜻입니다.
20 역주 콰드라틱 프로그래밍에 대해서는 <핸즈온 머신러닝 2판>(한빛미디어, 2018)의 5장을 참고하세요.