7.2.1 간단한 다수결 투표 분류기 구현
이 절에서 구현할 알고리즘은 여러 가지 분류 모델의 신뢰도에 가중치를 부여하여 연결할 수 있습니다. 여기서는 특정 데이터셋에서 개별 분류기의 약점을 보완하는 강력한 메타 분류기를 구축하는 것이 목표입니다. 수학적으로 표현하면 가중치가 적용된 다수결 투표는 다음과 같이 쓸 수 있습니다.
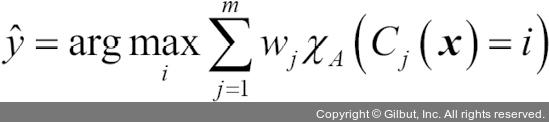
여기서 wj는 개별 분류기 Cj에 연관된 가중치입니다. 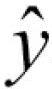 는 앙상블이 예측한 클래스 레이블입니다. A는 고유한 클래스 레이블의 집합입니다.
는 앙상블이 예측한 클래스 레이블입니다. A는 고유한 클래스 레이블의 집합입니다. 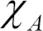 (그리스어로 카이(chi))는 특성 함수(characteristic function) 또는 지시 함수(indicator function)입니다. 이 함수는 j 번째 분류기의 예측 클래스가 i일 때(Cj(x) = i) 1을 반환합니다. 가중치가 동일하면 이 식을 다음과 같이 간단히 쓸 수 있습니다.
(그리스어로 카이(chi))는 특성 함수(characteristic function) 또는 지시 함수(indicator function)입니다. 이 함수는 j 번째 분류기의 예측 클래스가 i일 때(Cj(x) = i) 1을 반환합니다. 가중치가 동일하면 이 식을 다음과 같이 간단히 쓸 수 있습니다.
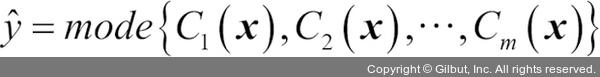
가중치 개념을 더욱 잘 이해하기 위해 좀 더 구체적인 예제를 살펴보겠습니다. 세 개의 분류기 Cj(j∈{1, 2, 3})가 있고 샘플 x의 클래스 레이블(Cj(x)∈{0, 1})을 예측해야 한다고 가정합시다. 세 개의 분류기 중 두 개가 클래스 0을 예측하고 C3 하나가 샘플을 클래스 1로 예측했습니다. 분류기 세 개의 예측 가중치가 동일하다면 다수결 투표는 이 샘플이 클래스 0에 속한다고 예측할 것입니다.


이제 C3에 가중치 0.6을 할당하고 C1과 C2에 0.2를 부여해 보겠습니다.4

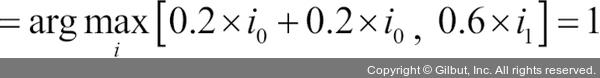
4 역주 다음 식에서 i0는 클래스 0일 때는 1이고, 그 외에는 0입니다. 마찬가지로 i1은 클래스 1일 때 1이고, 그 외에는 0입니다. 결국 [0.4, 0.6]에서 가장 큰 값의 인덱스를 찾는 문제가 됩니다.