6.2.1 홀드아웃 방법
전통적이고 널리 사용되는 머신 러닝 모델의 일반화 성능 추정 방법은 홀드아웃 교차 검증입니다. 홀드 아웃 방법은 초기 데이터셋을 별도의 훈련 데이터셋과 테스트 데이터셋으로 나눕니다. 전자는 모델 훈련에 사용하고 후자는 일반화 성능을 추정하는 데 사용합니다. 일반적인 머신 러닝 애플리케이션에서는 처음 본 데이터에서 예측 성능을 높이기 위해 하이퍼파라미터를 튜닝하고 비교해야 합니다. 이 과정을 모델 선택이라고 합니다. 모델 선택이란 이름은 주어진 분류 문제에서 튜닝할 파라미터(또는 하이퍼파라미터)의 최적 값을 선택해야 하는 것을 의미합니다. 모델 선택에 같은 테스트 데이터셋을 반복해서 재사용하면 훈련 데이터셋의 일부가 되는 셈이고 결국 모델은 과대적합될 것입니다. 아직도 많은 사람이 모델 선택을 위해 테스트 데이터셋을 사용합니다. 이는 좋은 머신 러닝 작업 방식이 아닙니다.
모델 선택에 홀드아웃 방법을 사용하는 가장 좋은 방법은 데이터를 훈련 데이터셋, 검증 데이터셋, 테스트 데이터셋 세 개의 부분으로 나누는 것입니다. 훈련 데이터셋은 여러 가지 모델을 훈련하는 데 사용합니다. 검증 데이터셋에 대한 성능은 모델 선택에 사용합니다. 훈련과 모델 선택 단계에서 모델이 만나지 못한 테스트 데이터셋을 분리했기 때문에 새로운 데이터에 대한 일반화 능력을 덜 편향되게 추정할 수 있는 장점이 있습니다. 그림 6-3은 홀드아웃 교차 검증의 개념을 보여 줍니다. 검증 데이터셋을 사용하여 반복적으로 다른 파라미터 값에서 모델을 훈련한 후 성능을 평가합니다. 만족할 만한 하이퍼파라미터 값을 얻었다면 테스트 데이터셋에서 모델의 일반화 성능을 추정합니다.
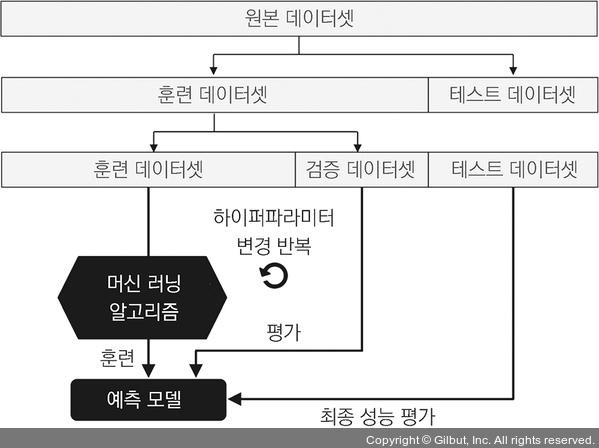
▲ 그림 6-3 홀드아웃 교차 검증
홀드아웃 방법은 훈련 데이터를 훈련 데이터셋과 검증 데이터셋으로 나누는 방법에 따라 성능 추정이 민감할 수 있다는 것이 단점입니다. 검증 데이터셋의 성능 추정이 어떤 샘플을 사용하느냐에 따라 달라질 것입니다. 다음 절에서 좀 더 안정적인 성능 추정 기법인 k-겹 교차 검증을 알아보겠습니다. 이 방법은 훈련 데이터를 k개의 부분으로 나누어 k번 홀드아웃 방법을 반복합니다.