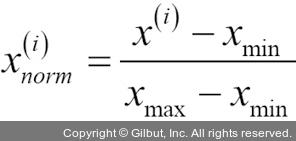4.4 특성 스케일 맞추기
특성 스케일 조정은 전처리 파이프라인에서 잊어버리기 쉽지만 아주 중요한 단계입니다. 결정 트리와 랜덤 포레스트(random forest)는 특성 스케일 조정에 대해 걱정할 필요가 없는 몇 안 되는 머신 러닝 알고리즘 중 하나입니다. 이런 알고리즘들은 스케일에 영향을 받지 않습니다. 2장에서 경사 하강법(gradient descent) 알고리즘을 구현하면서 보았듯이 대부분의 머신 러닝과 최적화 알고리즘은 특성의 스케일이 같을 때 훨씬 성능이 좋습니다.
특성 스케일 조정의 중요성은 간단한 예를 들어 설명할 수 있습니다. 두 개의 특성에서 첫 번째 특성이 1에서 10 사이 스케일을 가지고 있고 두 번째 특성은 1에서 10만 사이 스케일을 가진다고 가정해 보죠. 2장의 아달린에서 제곱 오차 함수를 생각해 보면 알고리즘은 대부분 두 번째 특성에 대한 큰 오차에 맞추어 가중치를 최적화할 것입니다. 유클리디안 거리 지표를 사용한 k-최근접 이웃(K-Nearest Neighbor, KNN)을 또 다른 예로 들 수 있습니다. 샘플 간의 거리를 계산하면 두 번째 특성 축에 좌우될 것입니다.
그럼 스케일이 다른 특성을 맞추는 대표적인 방법 두 가지인 정규화(normalization)와 표준화(standardization)에 대해 알아보겠습니다. 이 용어는 분야마다 조금씩 다르게 사용됩니다. 문맥에 따라 의미를 이해하는 것이 좋습니다. 대부분 정규화는 특성의 스케일을 [0, 1] 범위에 맞추는 것을 의미합니다. 최소-최대 스케일 변환(min-max scaling)의 특별한 경우입니다. 데이터를 정규화하기 위해 다음과 같이 각 특성의 열마다 최소-최대 스케일 변환을 적용하여 샘플 x(i)에서 새로운 값  을 계산합니다.
을 계산합니다.