6.5.2 분류 모델의 정밀도와 재현율 최적화
예측 오차(ERR)와 정확도(ACC) 모두 얼마나 많은 샘플을 잘못 분류했는지 일반적인 정보를 알려 줍니다. 오차는 잘못된 예측의 합을 전체 예측 샘플 개수로 나눈 것입니다. 정확도는 옳은 예측의 합을 전체 예측 샘플 개수로 나누어 계산합니다.

예측 정확도는 오차에서 바로 계산할 수 있습니다.
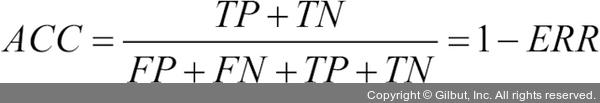
진짜 양성 비율(True Positive Rate, TPR)과 거짓 양성 비율(False Positive Rate, FPR)은 클래스 비율이 다른 경우 유용한 성능 지표입니다.16


예를 들어 종양 진단 문제에서는 환자가 적절한 치료를 받을 수 있도록 악성 종양을 감지하는 데 관심이 있습니다. 또 불필요하게 환자에게 걱정을 끼치지 않도록 음성 종양이 악성으로 분류되는 경우(FP)를 줄이는 것이 중요합니다. FPR에 비해서 TPR은 전체 양성 샘플(P) 중에서 올바르게 분류된 양성 (또는 관심) 샘플의 비율을 알려 줍니다.
정확도(PRE)와 재현율(REC) 성능 지표는 진짜 양성과 진짜 음성 샘플의 비율과 관련이 있습니다. 사실 REC는 TPR의 다른 이름입니다.


악성 종양 감지 문제에서 재현율을 최적화하면 악성 종양을 감지하지 못할 확률을 최소화하는 데 도움이 됩니다. 하지만 건강한 환자임에도 악성 종양으로 예측하는 비용이 발생합니다(높은 FP 때문입니다). 반대로 정밀도를 최적화하면 환자가 악성 종양을 가졌는지 정확히 예측하게 됩니다. 하지만 악성 종양 환자를 자주 놓치는 결과를 초래합니다(높은 FN 때문입니다).
PRE와 REC 최적화로 인한 장단점의 균형을 맞추기 위해 PRE와 REC를 조합한 F1-점수를 자주 사용합니다.

Note ≡ 정밀도와 재현율에 관한 추가 자료
정밀도와 재현율 같이 여러 가지 성능 지표에 대해 좀 더 자세한 설명을 읽고 싶다면 David M. W. Powers의 기술 리포트 Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation17을 참고하세요.
이런 성능 지표들이 모두 사이킷런에 구현되어 있습니다. 다음 예처럼 sklearn.metrics 모듈에서 임포트하여 사용합니다.
>>> from sklearn.metrics import precision_score
>>> from sklearn.metrics import recall_score, f1_score
>>> print('정밀도: %.3f' % precision_score(
... y_true=y_test, y_pred=y_pred))
정밀도: 0.976
>>> print('재현율: %.3f' % recall_score(
... y_true=y_test, y_pred=y_pred))
재현율: 0.952
>>> print('F1: %.3f' % f1_score(
... y_true=y_test, y_pred=y_pred))
F1: 0.964
또한, GridSearchCV의 scoring 매개변수를 사용하여 정확도 대신 다른 성능 지표를 사용할 수 있습니다. scoring 매개변수에 사용할 수 있는 전체 리스트는 온라인 문서를 참고하세요(http://scikit-learn.org/stable/modules/model_evaluation.html).
사이킷런에서 양성 클래스는 레이블이 1인 클래스입니다. 양성 레이블을 바꾸고 싶다면 make_scorer 함수를 사용하여 자신만의 함수를 만들 수 있습니다. 그다음 GridSearchCV의 scoring 매개변수에 전달할 수 있습니다. 예를 들어 f1_score를 측정 지표로 사용하는 경우는 다음과 같습니다.
>>> from sklearn.metrics import make_scorer, f1_score
>>> scorer = make_scorer(f1_score, pos_label=0)
>>> c_gamma_range = [0.01, 0.1, 1.0, 10.0]
>>> param_grid = [{'svc__C': c_gamma_range,
... 'svc__kernel': ['linear']},
... {'svc__C': c_gamma_range,
... 'svc__gamma': c_gamma_range,
... 'svc__kernel': ['rbf']}]
>>> gs = GridSearchCV(estimator=pipe_svc,
... param_grid=param_grid,
... scoring=scorer,
... cv=10)
>>> gs = gs.fit(X_train, y_train)
>>> print(gs.best_score_)
0.9861994953378878
>>> print(gs.best_params_)
{'svc__C': 10.0, 'svc__gamma': 0.01, 'svc__kernel': 'rbf'}
16 역주 TPR과 FPR은 오차 행렬에서 행(실제 클래스)끼리 계산하기 때문에 클래스 비율에 영향을 받지 않습니다.