이번에는 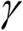 값을 크게 하고 결정 경계에 미치는 영향을 관찰해 보겠습니다.
값을 크게 하고 결정 경계에 미치는 영향을 관찰해 보겠습니다.
>>> svm = SVC(kernel='rbf', random_state=1, gamma=100.0, C=1.0)
>>> svm.fit(X_train_std, y_train)
>>> plot_decision_regions(X_combined_std,
... y_combined, classifier=svm,
... test_idx=range(105,150))
>>> plt.xlabel('petal length [standardized]')
>>> plt.ylabel('petal width [standardized]')
>>> plt.legend(loc='upper left')
>>> plt.tight_layout()
>>> plt.show()
결과 그래프를 보면 비교적 큰 값을 사용했기 때문에 클래스 0과 클래스 1 주위로 결정 경계가 매우 가깝게 나타납니다.
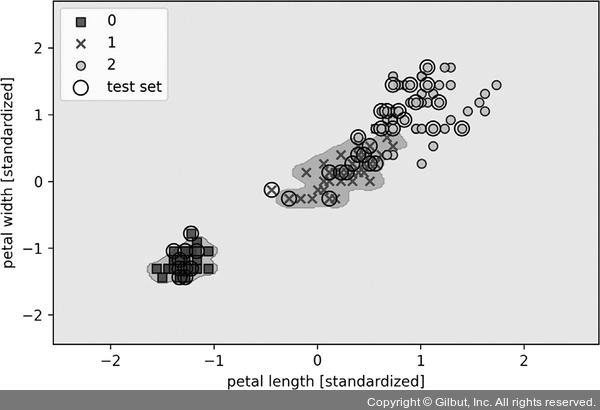
▲ 그림 3-16 감마 매개변수를 크게 한 RBF 커널 SVM의 결정 경계
이런 분류기는 훈련 데이터에서는 잘 맞지만 본 적 없는 데이터에서는 일반화 오차가 높을 것입니다. 알고리즘이 훈련 데이터셋 변화에 너무 민감할 때 매개변수가 과대적합 또는 분산을 조절하는 중요한 역할도 한다는 것을 알 수 있습니다.26
26 역주 SVM 모델에 규제를 가할 때는 gamma와 C 매개변수를 동시에 조절하는 것이 좋습니다.