3.6 결정 트리 학습
결정 트리(decision tree) 분류기는 설명이 중요할 때 아주 유용한 모델입니다. 결정 트리라는 이름처럼 일련의 질문에 대한 결정을 통해 데이터를 분해하는 모델로 생각할 수 있습니다.
결정 트리를 사용하여 어떤 날의 활동을 결정하는 예를 생각해 보죠.
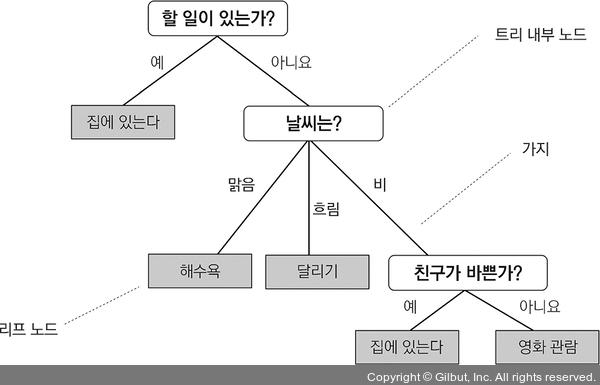
▲ 그림 3-17 어떤 일을 할지 선택하기 위한 결정 트리
결정 트리는 훈련 데이터에 있는 특성을 기반으로 샘플의 클래스 레이블을 추정할 수 있는 일련의 질문을 학습합니다. 그림 3-17은 범주형 변수를 사용한 결정 트리를 설명하고 있지만 동일한 개념이 붓꽃 데이터셋 같은 실수형 특성에도 적용됩니다. 예를 들어 꽃받침 너비 특성 축에 기준 값을 정하고 “꽃받침 너비가 2.8센티미터보다 큰가요?”라는 예/아니요 질문을 할 수 있습니다.
결정 알고리즘을 사용하면 트리의 루트(root)에서 시작해서 정보 이득(Information Gain, IG)이 최대가 되는 특성으로 데이터를 나눕니다. 정보 이득에 대해서는 다음 절에서 자세히 설명하겠습니다. 반복 과정을 통해 리프 노드(leaf node)가 순수해질 때까지 모든 자식 노드에서 이 분할 작업을 반복합니다. 즉, 각 노드의 모든 훈련 샘플은 동일한 클래스에 속합니다. 실제로 이렇게 하면 노드가 많은 깊은 트리가 만들어지고 과대적합될 가능성이 높습니다. 일반적으로 트리의 최대 깊이를 제한하여 트리를 가지치기(pruning)합니다.