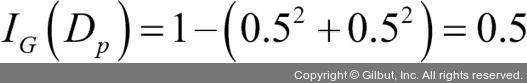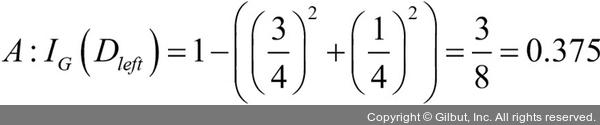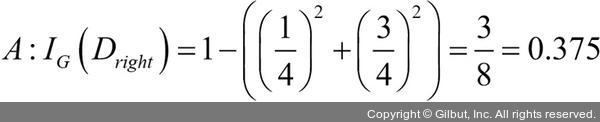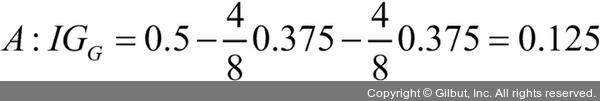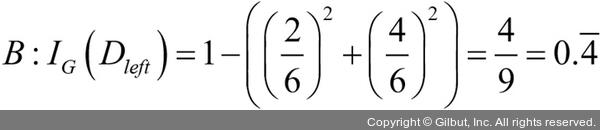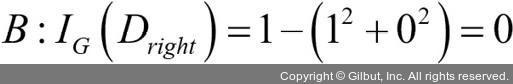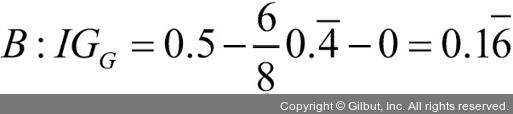부모 노드에서 데이터셋 Dp로 시작합니다. 이 데이터셋은 클래스 1이 40개의 샘플, 클래스 2가 40개의 샘플로 이루어져 있습니다. 이를 두 개의 데이터셋 Dleft와 Dright로 나눕니다. 분류 오차를 분할 기준으로 사용했을 때 정보 이득은 시나리오 A·B가 동일합니다(IGE = 0.25).
지니 불순도는 시나리오 A(IGG = 0.125)보다 시나리오 B()가 더 순수하기 때문에 값이 높습니다.
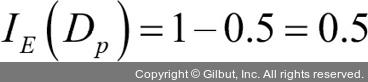
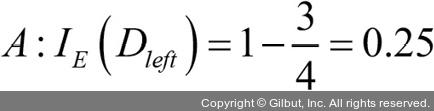
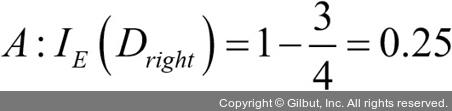
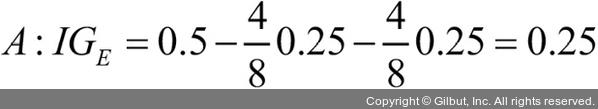
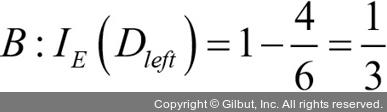
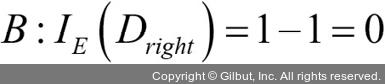
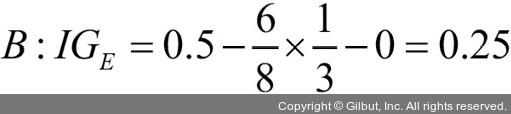
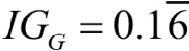 )가 더 순수하기 때문에 값이 높습니다.
)가 더 순수하기 때문에 값이 높습니다.