부트스트랩 샘플 크기가 작아지면 개별 트리의 다양성이 증가합니다. 특정 훈련 샘플이 부트스트랩 샘플에 포함될 확률이 낮기 때문입니다. 결국 부트스트랩 샘플 크기가 감소하면 랜덤 포레스트의 무작위성이 증가하고 과대적합의 영향이 줄어듭니다. 일반적으로 부트스트랩 샘플이 작을수록 랜덤 포레스트의 전체적인 성능이 줄어듭니다. 훈련 성능과 테스트 성능 사이에 격차가 작아지지만 전체적인 테스트 성능이 감소하기 때문입니다. 반대로 부트스트랩 샘플 크기가 증가하면 과대적합 가능성이 늘어납니다. 부트스트랩 샘플과 개별 결정 트리가 서로 비슷해지기 때문에 원본 훈련 데이터셋에 더 가깝게 학습됩니다.
사이킷런의 RandomForestClassifier를 포함하여 대부분의 라이브러리에서는 부트스트랩 샘플 크기를 원본 훈련 데이터셋의 샘플 개수와 동일하게 합니다.30 보통 이렇게 하면 균형 잡힌 편향 -분산 트레이드오프를 얻습니다. 분할에 사용할 특성 개수 d는 훈련 데이터셋에 있는 전체 특성 개수보다 작게 지정하는 편입니다. 사이킷런과 다른 라이브러리에서 사용하는 적당한 기본값은 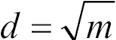 입니다.31 여기서 m은 훈련 데이터셋에 있는 특성 개수입니다.
입니다.31 여기서 m은 훈련 데이터셋에 있는 특성 개수입니다.
사이킷런에 이미 준비되어 있기 때문에 직접 개별 결정 트리를 만들어 랜덤 포레스트 분류기를 구성할 필요가 없습니다.
>>> from sklearn.ensemble import RandomForestClassifier
>>> forest = RandomForestClassifier(criterion='gini',
... n_estimators=25,
... random_state=1,
... n_jobs=2)
>>> forest.fit(X_train, y_train)
>>> plot_decision_regions(X_combined, y_combined,
... classifier=forest, test_idx=range(105, 150))
>>> plt.xlabel('petal length [cm]')
>>> plt.ylabel('petal width [cm]')
>>> plt.legend(loc='upper left')
>>> plt.tight_layout()
>>> plt.show()
30 역주 사이킷런 0.22 버전에서 부트스트랩 샘플 크기를 제어할 수 있는 max_samples 매개변수가 추가되었습니다. 원하는 부트스트랩 샘플 크기나 샘플의 비율을 지정합니다. 기본값은 None으로 훈련 데이터셋의 크기와 동일한 부트스트랩 샘플을 만듭니다.
31 역주 RandomForestClassifier 클래스의 max_features 매개변수 기본값이 'auto'로 특성 개수의 제곱근입니다. 랜덤 포레스트의 회귀를 구현한 RandomForestRegressor 클래스의 max_features 기본값은 훈련 데이터셋의 특성 개수와 동일합니다.