여기서도 StandardScaler 클래스의 fit 메서드를 훈련 데이터셋에만 딱 한 번 적용한 것을 주목하세요. 여기서 학습한 파라미터로 테스트 데이터셋과 새로운 데이터 포인트를 모두 변환합니다.
사이킷런에서 특성 스케일을 조정하는 다른 좋은 방법은 RobustScaler입니다. RobustScaler는 이상치가 많이 포함된 작은 데이터셋을 다룰 때 특히 도움이 되기 때문에 추천합니다. 비슷한 이유로 이 데이터셋에 적용된 머신 러닝 알고리즘이 과대적합되기 쉽다면 RobustScaler가 좋은 선택입니다. RobustScaler는 특성 열마다 독립적으로 작용하며 중간 값을 뺀 다음 데이터셋의 1사분위수와 3사분위수(즉, 25백분위수와 75백분위수)를 사용해서 데이터셋의 스케일을 조정합니다. 극단적인 값과 이상치에 영향을 덜 받습니다. 관심 있는 독자는 RobustScaler의 사이킷런 문서(https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.RobustScaler.html)를 참고하세요.
Note ≡
역주 RobustScaler는 중간 값(q2)을 빼고 1사분위수(q1)와 3사분위수(q3)의 차이로 나누어 데이터의 스케일을 조정합니다.
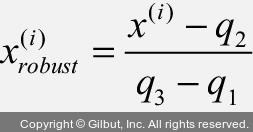
RobustScaler 사용법은 StandardScaler와 동일합니다.
>>> from sklearn.preprocessing import RobustScaler
>>> rbs = RobustScaler()
>>> X_train_robust = rbs.fit_transform(X_train)
>>> X_test_robust = rbs.fit_transform(X_test)
결과를 비교하기 위해 넘파이를 사용하여 직접 ex 배열을 변환해 보겠습니다.
>>> (ex - np.percentile(ex, 50)) / (np.percentile(ex, 75) - np.percentile(ex, 25))
array([-1. , -0.6, -0.2, 0.2, 0.6, 1. ])