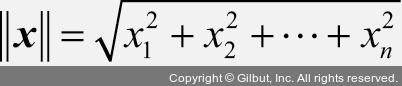RobustScaler는 fit() 메서드에 희소 행렬을 사용할 수 없지만 transform() 메서드에서 변환은 가능합니다.
>>> X_train_robust = rbs.transform(X_train_sparse)
StandardScaler는 with_mean=False로 지정하면 희소 행렬을 사용할 수 있습니다.
마지막으로 Normalizer 클래스와 normalize() 함수는 특성이 아니라 샘플별로 정규화를 수행합니다. 또한, 희소 행렬도 처리할 수 있습니다. 기본적으로 각 샘플의 L 2 노름이 1이 되도록 정규화합니다.
>>> from sklearn.preprocessing import Normalizer
>>> nrm = Normalizer()
>>> X_train_l2 = nrm.fit_transform(X_train)
Normalizer 클래스의 norm 매개변수에 사용할 노름을 지정할 수 있습니다. 'l1', 'l2', 'max'가 가능합니다. 기본값은 'l2'입니다. 이들의 차이점을 알아보기 위해 ex 배열을 사용하여 직접 계산해 보겠습니다. 원래 특성을 제곱한 열을 하나 더 추가하고 0 나눗셈 오류를 다루기 번거로우므로 편의상 0을 제외합니다.
>>> ex_2f = np.vstack((ex[1:], ex[1:]**2))
>>> ex_2f
array([[ 1, 2, 3, 4, 5],
[ 1, 4, 9, 16, 25]])
L 2 노름의 공식은 다음과 같습니다.