샘플별로 특성의 제곱을 더하기 위해 sum() 함수에서 axis=1을 사용합니다. 이 값의 제곱근을 구하면 L 2 노름입니다. 그다음 각 샘플의 특성을 해당 L 2 노름으로 나눕니다.
>>> l2_norm = np.sqrt(np.sum(ex_2f ** 2, axis=1))
>>> print(ex_2f)
[ 7.41619849 31.28897569]
>>> ex_2f / l2_norm.reshape(-1, 1)
array([[0.13483997, 0.26967994, 0.40451992, 0.53935989, 0.67419986],
[0.03196014, 0.12784055, 0.28764125, 0.51136222, 0.79900347]])
Normalizer 클래스에 norm='l1'으로 지정하면 절댓값인 L1 노름을 사용합니다. L1 노름의 공식은 다음과 같습니다.
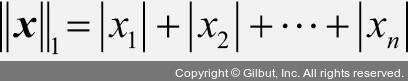
Normalizer(norm='l1')은 다음과 같이 절댓값인 L1 노름을 사용하여 각 샘플을 나눕니다.
>>> l1_norm = np.sum(np.abs(ex_2f), axis=1)
>>> print(l1_norm)
[15 55]
>>> ex_2f / l1_norm.reshape(-1, 1)
array([[0.06666667, 0.13333333, 0.2 , 0.26666667, 0.33333333],
[0.01818182, 0.07272727, 0.16363636, 0.29090909, 0.45454545]])
Normalizer(norm='max')는 각 샘플의 최대 절댓값을 사용하여 나눕니다.
>>> max_norm = np.max(np.abs(ex_2f), axis=1)
>>> print(max_norm)
[ 5 25]
>>> ex_2f / max_norm.reshape(-1, 1)
array([[0.2 , 0.4 , 0.6 , 0.8 , 1. ],
[0.04, 0.16, 0.36, 0.64, 1. ]])