solver = 'liblinear'로 초기화한 LogisticRegression 객체를 다중 클래스 데이터셋에 적용하면 OvR(One-versus-Rest) 방식을 사용합니다. 따라서 첫 번째 절편은 클래스 1을 클래스 2·3과 구분하는 모델에 속한 것입니다. 두 번째는 클래스 2를 클래스 1·3과 구분하는 모델의 절편입니다. 세 번째는 클래스 3을 클래스 1·2와 구분하는 모델의 절편입니다.
>>> lr.coef_
array([[ 1.24567209, 0.18072301, 0.74682115, -1.16438451, 0. ,
0. , 1.1595535 , 0. , 0. , 0. ,
0. , 0.55864751, 2.50891241],
[-1.53644846, -0.38769843, -0.99485417, 0.36489012, -0.05989298,
0. , 0.66853184, 0. , 0. , -1.93460212,
1.23246414, 0. , -2.23212696],
[ 0.1355558 , 0.16880291, 0.35718019, 0. , 0. ,
0. , -2.43768478, 0. , 0. , 1.5635432 ,
-0.81834553, -0.4930494 , 0. ]])
lr.coef_ 속성에 있는 가중치는 클래스마다 벡터 하나씩 세 개의 행이 있는 가중치 배열입니다. 각 행은 13개의 가중치를 가집니다. 각 가중치와 13차원의 Wine 데이터셋의 특성을 곱해 최종 입력을 계산합니다.
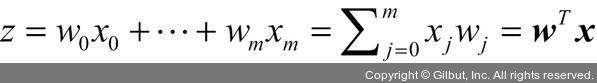
Note ≡ 사이킷런 추정기의 가중치와 절편 참조하기
사이킷런에서 intercept_는 w0에 해당하며 coef_에 있는 값은 j > 0인 wj입니다.