코드를 실행하면 Wine 데이터셋 특성의 상대적인 중요도에 따른 순위를 그래프로 그립니다. 특성 중요도는 합이 1이 되도록 정규화된 값입니다.
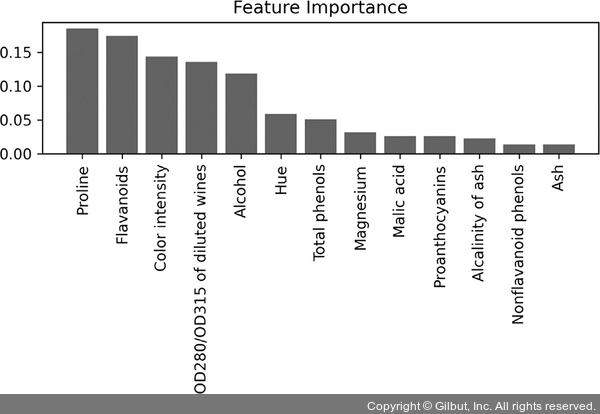
▲ 그림 4-10 랜덤 포레스트 모델의 특성 중요도
500개의 결정 트리에서 평균적인 불순도 감소를 기반으로 이 데이터셋에서 가장 판별력이 좋은 특성은 Proline, Flavanoids, Color intensity, OD280/OD315 of diluted wines, Alcohol입니다. 재미있게도 이 그래프에서 높은 순위에 위치한 특성 중 두 개는 이전 절에서 구현한 SBS 알고리즘으로 선택한 세 개의 특성에 들어 있습니다(Alcohol과 OD280/OD315 of diluted wines).
모델 해석을 중요하게 고려한다면 랜덤 포레스트 기법에서 언급할 만한 중요한 참고 사항이 있습니다. 랜덤 포레스트에서 두 개 이상의 특성이 매우 상관관계가 높다면 하나의 특성은 매우 높은 순위를 갖지만 다른 특성 정보는 완전히 잡아내지 못할 수 있습니다. 특성 중요도 값을 해석하는 것보다 모델의 예측 성능에만 관심이 있다면 이 문제를 신경 쓸 필요는 없습니다.