마지막으로 124×2 차원의 행렬로 변환된 Wine 훈련 데이터셋을 2차원 산점도로 시각화해 봅시다.
>>> colors = ['r', 'b', 'g']
>>> markers = ['s', 'x', 'o']
>>> for l, c, m in zip(np.unique(y_train), colors, markers):
... plt.scatter(X_train_pca[y_train==l, 0],
... X_train_pca[y_train==l, 1],
... c=c, label=l, marker=m)
>>> plt.xlabel('PC 1')
>>> plt.ylabel('PC 2')
>>> plt.legend(loc='lower left')
>>> plt.tight_layout()
>>> plt.show()
결과 그래프에서 볼 수 있듯이 데이터가 y축(두 번째 주성분)보다 x축(첫 번째 주성분)을 따라 더 넓게 퍼져 있습니다. 이전 절에서 만든 설명된 분산의 그래프와 동일한 결과입니다.7 선형 분류기가 클래스들을 잘 분리할 수 있을 것 같다고 직관적으로 알 수 있습니다.
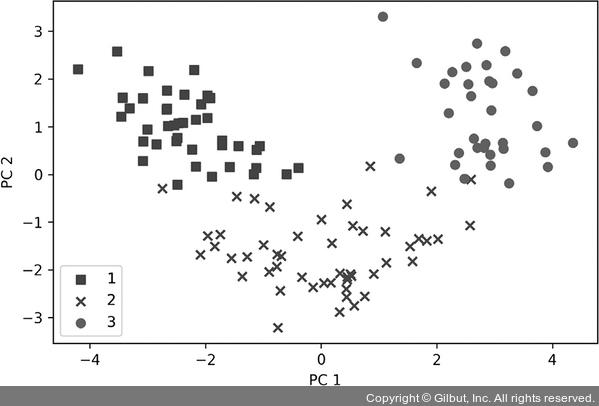
▲ 그림 5-3 차원 축소된 Wine 데이터셋의 산점도
산점도를 그리기 위한 목적으로 클래스 레이블 정보를 사용했습니다. 하지만 PCA는 어떤 클래스 레이블 정보도 사용하지 않는 비지도 학습 기법이라는 점을 잊지 마세요.
7 역주 주성분은 고윳값의 크기로 정렬하기 때문에 첫 번째 주성분이 가장 큰 분산을 가집니다.