결과 그래프에서 볼 수 있듯이 처음 두 개의 선형 판별 벡터가 Wine 데이터셋에 있는 정보 중 거의 100%를 잡아냅니다.
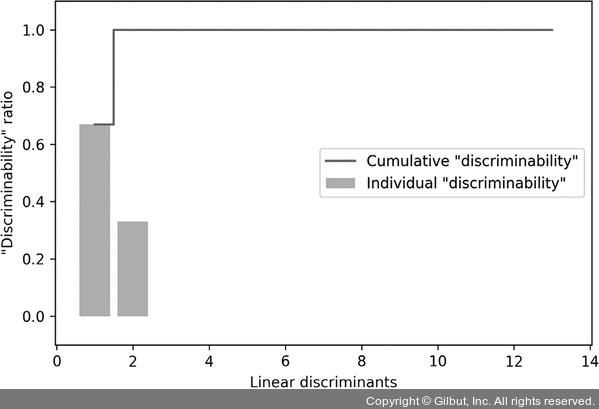
▲ 그림 5-7 선형 판별 분석의 설명된 분산
두 개의 판별 고유 벡터를 열로 쌓아서 변환 행렬 W를 만들어 봅시다.
>>> w = np.hstack((eigen_pairs[0][1][:, np.newaxis].real,
... eigen_pairs[1][1][:, np.newaxis].real))
>>> print('행렬 W:\n', w)
행렬 W:
[[-0.1481 -0.4092]
[ 0.0908 -0.1577]
[-0.0168 -0.3537]
[ 0.1484 0.3223]
[-0.0163 -0.0817]
[ 0.1913 0.0842]
[-0.7338 0.2823]
[-0.075 -0.0102]
[ 0.0018 0.0907]
[ 0.294 -0.2152]
[-0.0328 0.2747]
[-0.3547 -0.0124]
[-0.3915 -0.5958]]