규제 강도를 낮추어 로지스틱 회귀 모델이 훈련 데이터셋의 모든 샘플을 정확하게 분류하도록 결정 경계를 옮길 수 있습니다. 하지만 더 중요한 것은 테스트 데이터셋의 결과입니다.
>>> X_test_lda = lda.transform(X_test_std)
>>> plot_decision_regions(X_test_lda, y_test, classifier=lr)
>>> plt.xlabel('LD 1')
>>> plt.ylabel('LD 2')
>>> plt.legend(loc='lower left')
>>> plt.tight_layout()
>>> plt.show()
다음 그래프에서 볼 수 있듯이 로지스틱 회귀 분류기는 원본 13개의 와인 특성 대신 2차원의 특성 부분 공간을 사용해서 테스트 데이터셋에 있는 모든 샘플을 완벽하게 분류했습니다.
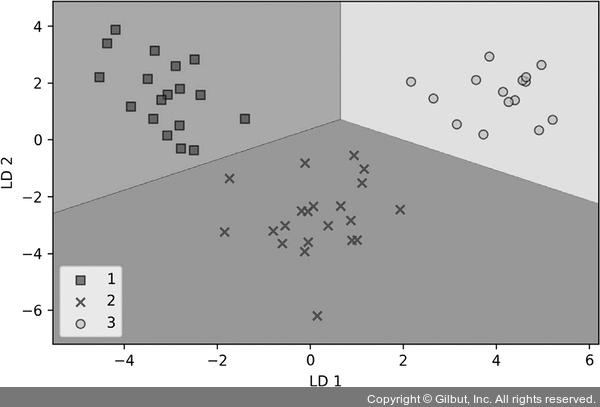
▲ 그림 5-10 로지스틱 회귀의 예측 결과