지금까지 배운 것을 요약하면 RBF 커널 PCA를 구현하기 위해 다음 세 단계를 정의할 수 있습니다.
1. 커널 (유사도) 행렬 K를 다음 식으로 계산합니다.

샘플의 모든 쌍에 대해 구합니다.

예를 들어 100개의 훈련 샘플이 담긴 데이터셋이라면 각 쌍의 유사도를 담은 대칭 커널 행렬은 100×100 차원이 됩니다.
2. 다음 식을 사용하여 커널 행렬 K를 중앙에 맞춥니다.

여기서 1n은 모든 값이  인 n×n 차원 행렬입니다(커널 행렬과 같은 차원입니다).
인 n×n 차원 행렬입니다(커널 행렬과 같은 차원입니다).
3. 고윳값 크기대로 내림차순으로 정렬하여 중앙에 맞춘 커널 행렬에서 최상위 k개의 고유 벡터를 고릅니다. 표준 PCA와 다르게 고유 벡터는 주성분 축이 아니며, 이미 이 축에 투영된 샘플입니다.
여기서 두 번째 단계에서 왜 커널 행렬을 중앙에 맞추었는지 궁금할지 모르겠습니다. 앞서 우리는 표준화 전처리된 데이터를 다룬다고 가정했습니다. 공분산 행렬을 구성하고 비선형 특성 조합으로 점곱을 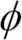 를 사용한 비선형 특성 조합으로 대체할 때 사용한 모든 특성의 평균이 0입니다. 반면 새로운 특성 공간을 명시적으로 계산하지 않기 때문에 이 특성 공간이 중앙에 맞추어져 있는지 보장할 수 없습니다. 이것이 새로운 두 번째 단계에서 커널 행렬의 중앙을 맞추는 것이 필요한 이유입니다.
를 사용한 비선형 특성 조합으로 대체할 때 사용한 모든 특성의 평균이 0입니다. 반면 새로운 특성 공간을 명시적으로 계산하지 않기 때문에 이 특성 공간이 중앙에 맞추어져 있는지 보장할 수 없습니다. 이것이 새로운 두 번째 단계에서 커널 행렬의 중앙을 맞추는 것이 필요한 이유입니다.