확실히 이 반달 모양 데이터셋은 선형적으로 구분되지 않습니다. 우리의 목표는 커널 PCA로 반달 모양을 펼쳐서 선형 분류기에 적합한 입력 데이터셋으로 만드는 것입니다. 먼저 기본 PCA의 주성분에 데이터셋을 투영하면 어떻게 보이는지 확인해 보죠.
>>> from sklearn.decomposition import PCA
>>> scikit_pca = PCA(n_components=2)
>>> X_spca = scikit_pca.fit_transform(X)
>>> fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(7,3))
>>> ax[0].scatter(X_spca[y==0, 0], X_spca[y==0, 1],
... color='red', marker='^', alpha=0.5)
>>> ax[0].scatter(X_spca[y==1, 0], X_spca[y==1, 1],
... color='blue', marker='o', alpha=0.5)
>>> ax[1].scatter(X_spca[y==0, 0], np.zeros((50,1))+0.02,
... color='red', marker='^', alpha=0.5)
>>> ax[1].scatter(X_spca[y==1, 0], np.zeros((50,1))-0.02,
... color='blue', marker='o', alpha=0.5)
>>> ax[0].set_xlabel('PC1')
>>> ax[0].set_ylabel('PC2')
>>> ax[1].set_ylim([-1, 1])
>>> ax[1].set_yticks([])
>>> ax[1].set_xlabel('PC1')
>>> plt.show()
구해진 결과를 보면 확실히 기본 PCA로 변환된 데이터셋을 선형 분류기가 잘 구분할 수 없을 것 같습니다.
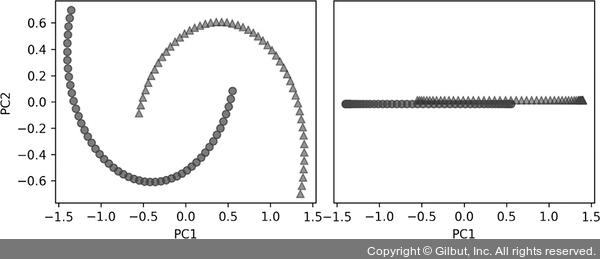
▲ 그림 5-13 PCA를 적용한 반달 모양 데이터셋