사이킷런의 Pipeline 클래스를 메타 추정기(meta-estimator)나 개별 변환기와 추정기를 감싼 래퍼(wrapper)로 생각할 수 있습니다. Pipeline 객체의 fit 메서드를 호출하면 데이터가 중간 단계에 있는 모든 변환기의 fit 메서드와 transform 메서드를 차례로 거쳐 추정기 객체(파이프라인의 마지막 단계)에 도달합니다. 추정기는 변환된 훈련 데이터셋을 사용하여 학습합니다.
앞선 예제에서 pipe_lr 파이프라인의 fit 메서드를 호출할 때 먼저 훈련 데이터셋에 StandardScaler 의 fit 메서드와 transform 메서드가 호출됩니다. 변환된 훈련 데이터는 파이프라인의 다음 요소인 PCA 객체로 전달됩니다. 이전 단계와 비슷하게 스케일 조정된 입력 데이터에 PCA의 fit 메서드와 transform 메서드가 호출됩니다. 그다음 파이프라인의 최종 요소인 추정기에 훈련 데이터가 전달됩니다.
마침내 LogisticRegression 추정기가 StandardScaler와 PCA로 변환된 훈련 데이터로 학습합니다. 다시 언급하지만 파이프라인의 중간 단계 횟수는 제한이 없습니다. 파이프라인의 마지막 요소는 추정기가 되어야 합니다.
파이프라인에서 fit 메서드를 호출하는 것과 비슷하게 predict 메서드도 제공합니다. Pipeline 인스턴스의 predict 메서드를 호출할 때 주입된 데이터는 중간 단계의 transform 메서드를 통과합니다. 마지막 단계에서 추정기 객체가 변환된 데이터에 대한 예측을 반환합니다.
사이킷런의 파이프라인은 매우 유용한 래퍼 도구입니다. 책 나머지 부분에서 자주 사용하게 될 것입니다. Pipeline 객체가 동작하는 방식을 확실하게 이해하기 위해 그림 6-1을 자세히 살펴보세요. 이전 문단에서 설명한 것을 요약했습니다.
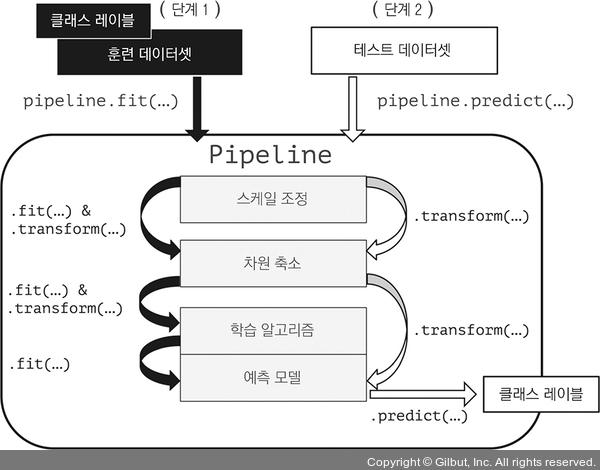
▲ 그림 6-1 사이킷런의 파이프라인 작동 방식