또한, 각 폴드의 추정 성능 Ei(예를 들어 분류 정확도 또는 오차)를 사용하여 모델의 평균 성능 E를 계산합니다.
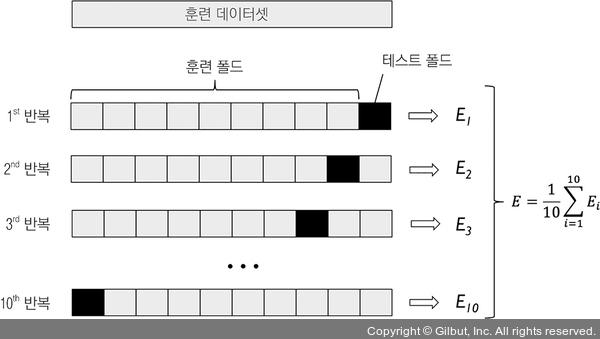
▲ 그림 6-4 k-겹 교차 검증
경험적으로 보았을 때 k-겹 교차 검증에서 좋은 기본값은 k = 10입니다. 예를 들어 론 코하비(Ron Kohavi)는 여러 종류의 실제 데이터셋에서 수행한 실험을 통해 10-겹 교차 검증이 가장 뛰어난 편향 -분산 트레이드오프를 가진다고 제안했습니다.3
비교적 작은 훈련 데이터셋으로 작업한다면 폴드 개수를 늘리는 것이 좋습니다. k 값이 증가하면 더 많은 훈련 데이터가 각 반복에 사용되고 모델 성능을 평균하여 일반화 성능을 추정할 때 더 낮은 편향을 만듭니다. k 값이 아주 크면 교차 검증 알고리즘의 실행 시간이 늘어나고 분산이 높은 추정을 만듭니다. 이는 훈련 폴드가 서로 많이 비슷해지기 때문입니다. 다른 말로 하면 대규모 데이터셋으로 작업할 때는 k = 5와 같은 작은 k 값을 선택해도 모델의 평균 성능을 정확하게 추정할 수 있습니다. 또 폴드마다 모델을 학습하고 평가하는 계산 비용을 줄일 수 있습니다.
Note ≡ LOOCV 방법
k-겹 교차 검증의 특별한 경우는 LOOCV(Leave-One-Out Cross-Validation) 방법입니다. LOOCV에서는 폴드 개수가 훈련 샘플 개수와 같습니다(k = n). 즉, 하나의 훈련 샘플이 각 반복에서 테스트로 사용됩니다. 이 방법은 아주 작은 데이터셋을 사용할 때 권장됩니다.4
3 A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection, Kohavi, Ron, International Joint Conference on Artificial Intelligence (IJCAI), 14 (12): 1137-43, 1995
4 역주 사이킷런의 sklearn.model_selection 패키지 밑에 LOOCV 방법을 구현한 LeaveOneOut 클래스가 있습니다.