LogisticRegression 클래스 객체를 만들 때 max_iter=10000 매개변수 값을 전달했습니다(기본값은 1000입니다). 이는 (다음 절에 나올) 큰 규제 매개변수 값이나 작은 데이터셋 크기에서 발생할 수 있는 수렴 문제를 피하기 위해서입니다. 이 코드를 실행하면 다음 학습 곡선을 얻게 됩니다.
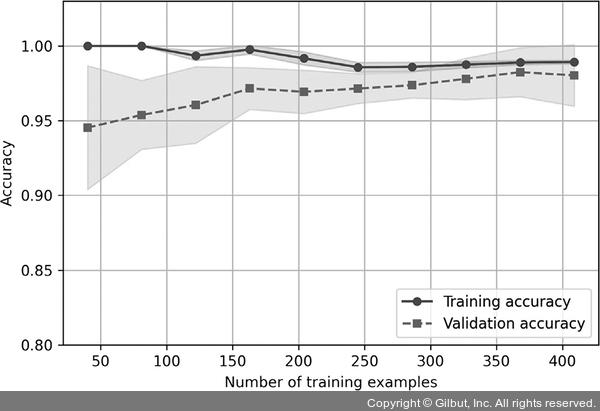
▲ 그림 6-6 학습 곡선
learning_curve 함수의 train_sizes 매개변수를 통해 학습 곡선을 생성하는 데 사용할 훈련 샘플의 개수나 비율을 지정할 수 있습니다. 여기서는 train_sizes = np.linspace(0.1, 1.0, 10)으로 지정해서 일정한 간격으로 훈련 데이터셋의 비율 열 개를 설정했습니다. 기본적으로 learning_curve 함수는 계층별 k-겹 교차 검증을 사용하여 분류기의 교차 검증 정확도를 계산합니다. cv 매개변수를 통해 k 값을 10으로 지정했기 때문에 계층별 10-겹 교차 검증을 사용합니다.
반환된 훈련과 테스트 교차 검증 점수로부터 훈련 데이터셋 크기별로 평균 정확도를 계산하여 맷플롯립의 plot 함수를 사용해서 그래프를 그립니다. fill_between 함수를 사용하여 그래프에 평균 정확도의 표준 편차를 그려서 추정 분산을 나타냈습니다.