6.5.4 다중 분류의 성능 지표
이 절에서 언급한 성능 지표는 이진 분류에 대한 것입니다. 사이킷런은 이런 평균 지표에 마크로(macro)와 마이크로(micro) 평균 방식을 구현하여 OvA(One-versus-All) 방식을 사용하는 다중 분류로 확장합니다. 마이크로 평균은 클래스별로 TP, TN, FP, FN을 계산합니다. 예를 들어 k개의 클래스가 있는 경우 정밀도의 마이크로 평균은 다음과 같이 계산합니다.

마크로 평균은 단순하게 클래스별 정밀도의 평균입니다.
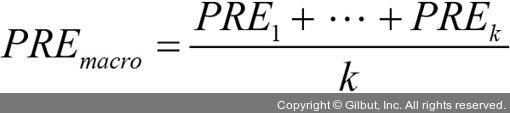
마이크로 평균은 각 샘플이나 예측에 동일한 가중치를 부여하고자 할 때 사용합니다. 마크로 평균은 모든 클래스에 동일한 가중치를 부여하여 분류기의 전반적인 성능을 평가합니다. 이 방식에서는 가장 빈도 높은 클래스 레이블의 성능이 중요합니다.
사이킷런에서 이진 성능 지표로 다중 분류 모델을 평가하면 정규화 또는 가중치가 적용된 마크로 평균이 기본으로 적용됩니다.20 가중치가 적용된 마크로 평균은 평균을 계산할 때 각 클래스 레이블의 샘플 개수를 가중하여 계산합니다. 가중치가 적용된 마크로 평균은 레이블마다 샘플 개수가 다른 불균형한 클래스를 다룰 때 유용합니다.
사이킷런에서 가중치가 적용된 마크로 평균이 다중 분류 문제에서 기본값이지만 sklearn.metrics 모듈 아래에 있는 측정 함수들은 average 매개변수로 평균 계산 방식을 지정할 수 있습니다. 예를 들어 precision_score나 make_scorer 함수입니다.
>>> pre_scorer = make_scorer(score_func=precision_score,
... pos_label=1,
... greater_is_better=True,
... average='micro')
이 장에서 불균형한 클래스에 대해 여러 번 언급했지만 실제로 이런 경우에 적절한 처리 방법을 설명하지 않았습니다. 클래스 불균형은 실전 데이터를 다룰 때 매우 자주 나타나는 문제입니다. 한 개 또는 여러 개의 클래스 샘플이 데이터셋에 너무 많을 때입니다. 이런 문제가 일어날 수 있는 분야는 스팸 필터링, 부정 감지, 질병 차단 등입니다.
20 역주 sklearn.metrics 모듈의 classification_report 함수는 정밀도, 재현율, F1- 점수를 한 번에 계산하여 출력해 줍니다. 이 함수를 다중 분류 모델에 적용하면 가중치가 적용된 마크로 평균을 계산합니다. 사이킷런 0.20 버전부터는 마이크로, 마크로, 가중치 마크로 값을 모두 계산하여 반환합니다. precision_score, recall_score 등의 함수에 average 매개변수 기본값은 이진 분류일 경우에 해당하는 'binary'입니다. 다중 분류에서 마이크로, 마크로, 가중치 마크로 평균을 사용하려면 각각 'micro', 'macro', 'weighted'로 지정합니다.