먼저 훈련 데이터셋을 사용하여 m개의 다른 분류기( )를 훈련시킵니다. 앙상블 방법에 따라 결정 트리, 서포트 벡터 머신, 로지스틱 회귀 분류기와 같은 여러 가지 알고리즘을 사용하여 구축할 수 있습니다. 또는 같은 분류 알고리즘을 사용하고 훈련 데이터셋의 부분 집합(subset)을 달리하여 학습할 수도 있습니다. 유명한 앙상블 방법 중 하나는 서로 다른 결정 트리를 연결한 랜덤 포레스트(random forest)입니다. 그림 7-2는 과반수 투표를 사용한 일반적인 앙상블 방법입니다.
)를 훈련시킵니다. 앙상블 방법에 따라 결정 트리, 서포트 벡터 머신, 로지스틱 회귀 분류기와 같은 여러 가지 알고리즘을 사용하여 구축할 수 있습니다. 또는 같은 분류 알고리즘을 사용하고 훈련 데이터셋의 부분 집합(subset)을 달리하여 학습할 수도 있습니다. 유명한 앙상블 방법 중 하나는 서로 다른 결정 트리를 연결한 랜덤 포레스트(random forest)입니다. 그림 7-2는 과반수 투표를 사용한 일반적인 앙상블 방법입니다.
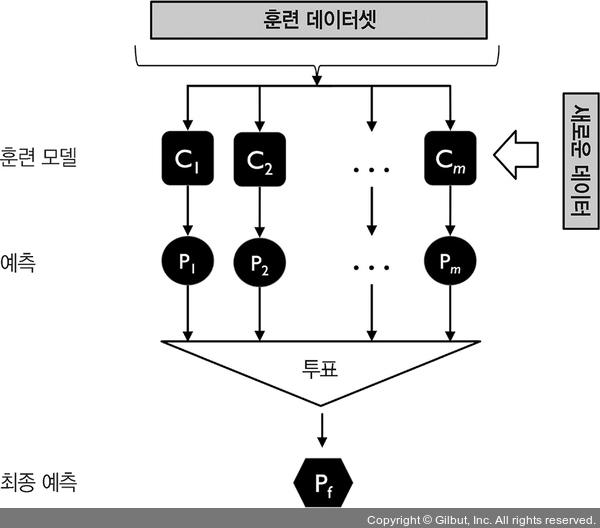
▲ 그림 7-2 과반수 투표를 사용한 앙상블 방법
과반수 투표나 다수결 투표로 클래스 레이블을 예측하려면 개별 분류기 Cj의 예측 레이블을 모아 가장 많은 표를 받은 레이블 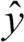 를 선택합니다.
를 선택합니다.
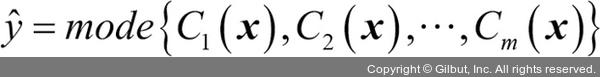
(통계학에서 최빈값은 집합에서 가장 많이 나타나는 이벤트 또는 결과입니다. 예를 들어 mod{1, 2, 1, 1, 2, 4, 5, 4} = 1입니다.)