직관적으로 생각했을 때 3×0.2 = 0.6이기 때문에 C3의 예측이 C1이나 C2의 예측보다 3배 더 가중됩니다. 즉, 다음과 같이 쓸 수 있습니다.

argmax와 bincount 함수5를 사용하여 가중치가 적용된 다수결 투표를 파이썬 코드로 구현할 수 있습니다.
>>> import numpy as np
>>> np.argmax(np.bincount([0, 0, 1],
... weights=[0.2, 0.2, 0.6]))
1
3장에서 로지스틱 회귀에 대해 언급했던 것처럼 사이킷런의 일부 분류기는 predict_proba 메서드에서 예측 클래스 레이블의 확률을 반환할 수 있습니다. 앙상블의 분류기가 잘 보정(calibration)6 되어 있다면 다수결 투표에서 클래스 레이블 대신 예측 클래스 확률을 사용하는 것이 좋습니다. 확률을 사용하여 클래스 레이블을 예측하는 다수결 투표 버전은 다음과 같이 쓸 수 있습니다.
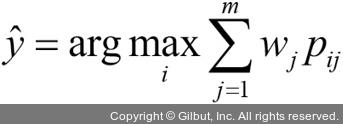
여기서 Pij는 클래스 레이블 i에 대한 j번째 분류기의 예측 확률입니다.
앞선 예제에 이어서 클래스 레이블 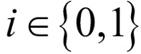 인 이진 분류 문제에서 세 개의 분류기로 구성된 앙상블 Cj(
인 이진 분류 문제에서 세 개의 분류기로 구성된 앙상블 Cj(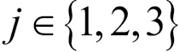 )을 가정해 보죠. 어떤 샘플 x에 대한 분류기 Cj는 다음과 같은 클래스 소속 확률을 반환합니다.
)을 가정해 보죠. 어떤 샘플 x에 대한 분류기 Cj는 다음과 같은 클래스 소속 확률을 반환합니다.
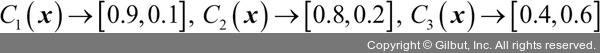
5 역주 bincount 함수는 0 이상의 정수로 된 배열을 입력받아 각 정수가 등장하는 횟수를 카운트합니다. 정수 값에 해당하는 인덱스 위치에 카운트가 저장된 배열이 반환됩니다. 예를 들어 np.bincount([0, 2, 0])은 [2, 0, 1]이 반환됩니다. 정수가 아니라 실수가 입력되면 소수점 이하를 버립니다. weights 배열이 주어지면 카운트 대신 입력 배열과 같은 위치의 weights 값을 더합니다. 본문의 예에서처럼 np.bincount([0, 0, 1], weights=[0.2, 0.2, 0.6])은 [0.4, 0.6] 넘파이 배열이 반환됩니다. np.argmax는 배열에서 가장 큰 값을 가진 위치의 인덱스를 반환합니다.
6 역주 보정이 잘 되어 있다는 뜻은 predict_proba 메서드에서 0.7의 확률을 얻은 샘플 중에 실제로 70%가 양성 클래스에 속한다는 의미입니다. 사이킷런에서는 sklearn.calibration.CalibratedClassifierCV 클래스를 사용하여 보정된 분류기를 훈련시킬 수 있습니다.