결과 그래프에서 보듯이 결정 트리의 선형 결정 경계가 배깅 앙상블에서 더 부드러워졌습니다.
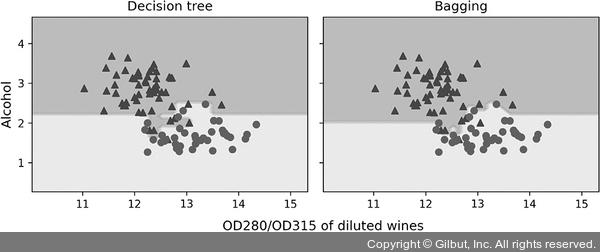
▲ 그림 7-8 결정 트리와 배깅의 결정 경계
이 절에서는 아주 간단한 배깅 예제를 보았습니다. 실전에서 고차원 데이터셋을 사용하는 더 복잡한 분류 문제라면 단일 결정 트리가 쉽게 과대적합될 수 있습니다. 이런 경우에 배깅 알고리즘의 강력함이 제대로 발휘될 수 있습니다. 마지막으로 배깅 알고리즘은 모델의 분산을 감소하는 효과적인 방법이지만 모델의 편향을 낮추는 데는 효과적이지 않습니다. 즉, 모델이 너무 단순해서 데이터에 있는 경향을 잘 잡아내지 못합니다. 이것이 배깅을 수행할 때 편향이 낮은 모델, 예를 들어 가지치기하지 않은 결정 트리를 분류기로 사용하여 앙상블을 만드는 이유입니다.
Note ≡
역주 랜덤 포레스트와 배깅은 모두 기본적으로 부트스트랩 샘플링을 사용하기 때문에 분류기마다 훈련에 사용하지 않는 여분의 샘플이 남습니다. 이를 OOB(Out Of Bag) 샘플이라고 합니다. 이를 사용하면 검증 데이터셋을 만들지 않고 앙상블 모델을 평가할 수 있습니다. 사이킷런에서는 oob_score 매개변수를 True로 설정하면 됩니다. 이 매개변수의 기본값은 False입니다.
사이킷런의 랜덤 포레스트는 분류일 경우 OOB 샘플에 대한 각 트리의 예측 확률을 누적하여 가장 큰 확률을 가진 클래스를 타깃과 비교하여 정확도를 계산합니다. 회귀일 경우에는 각 트리의 예측 평균에 대한 R2 점수를 계산합니다. 이 점수는 oob_score_ 속성에 저장되어 있습니다. RandomForestClassifier에 Wine 데이터셋을 적용하여 OOB 점수를 계산해 보겠습니다.
>>> from sklearn.ensemble import RandomForestClassifier
>>> rf = RandomForestClassifier(oob_score=True,
... random_state=1)
>>> rf.fit(X_train, y_train)
>>> print('랜덤 포레스트의 훈련 정확도/테스트 정확도 %.3f/%.3f' %
... (rf.score(X_train, y_train), rf.score(X_test, y_test)))
>>> print('랜덤 포레스트의 OOB 정확도 %.3f' % rf.oob_score_)
랜덤 포레스트의 훈련 정확도/테스트 정확도 1.000/0.917
랜덤 포레스트의 OOB 정확도 0.884
배깅의 OOB 점수 계산 방식은 랜덤 포레스트와 거의 동일합니다. 다만 base_estimator에 지정된 분류기가 predict_proba 메서드를 지원하지 않을 경우 예측 클래스를 카운팅하여 가장 높은 값의 클래스를 사용해서 정확도를 계산합니다. 본문에서 만든 것과 동일한 BaggingClassifier 모델을 만들고 OOB 점수를 계산해 보겠습니다.
>>> bag = BaggingClassifier(base_estimator=tree,
... n_estimators=500,
... oob_score=True,
... random_state=1)
>>> bag.fit(X_train, y_train)
>>> print('배깅의 훈련 정확도/테스트 정확도 %.3f/%.3f' %
... (bag.score(X_train, y_train), bag.score(X_test, y_test)))
>>> print('배깅의 OOB 정확도 %.3f' % bag.oob_score_)
배깅의 훈련 정확도/테스트 정확도 1.000/0.917
배깅의 OOB 정확도 0.895