7.4.1 부스팅 작동 원리
배깅과는 달리 부스팅의 초창기 방법은 중복을 허용하지 않고 훈련 데이터셋에서 랜덤 샘플을 추출하여 부분 집합을 구성합니다. 원본 부스팅 과정은 다음 네 개의 주요 단계로 요약할 수 있습니다.
1. 훈련 데이터셋 D에서 중복을 허용하지 않고 랜덤한 부분 집합 d1을 뽑아 약한 학습기 C1을 훈련합니다.
2. 훈련 데이터셋에서 중복을 허용하지 않고 두 번째 랜덤한 훈련 부분 집합 d2를 뽑고 이전에 잘못 분류된 샘플의 50%를 더해서 약한 학습기 C2를 훈련합니다.
3. 훈련 데이터셋 D에서 C1과 C2에서 잘못 분류한 훈련 샘플 d3를 찾아 세 번째 약한 학습기인 C3를 훈련합니다.
4. 약한 학습기 C1, C2, C3를 다수결 투표로 연결합니다.
레오 브레이만이 언급한 것처럼18 부스팅은 배깅 모델에 비해 분산은 물론 편향도 감소시킬 수 있습니다. 실제로는 에이다부스트 같은 부스팅 알고리즘이 분산이 높다고 알려져 있습니다. 즉, 훈련 데이터에 과대적합되는 경향이 있습니다.19
여기서 언급한 원본 부스팅 방법과는 다르게 에이다부스트는 약한 학습기를 훈련할 때 훈련 데이터셋 전체를 사용합니다.20 훈련 샘플은 반복마다 가중치가 다시 부여되며 이 앙상블은 이전 학습기의 실수를 학습하는 강력한 분류기를 만듭니다.
에이다부스트 알고리즘을 구체적으로 깊게 알아보기 전에 그림 7- 9로 에이다부스트의 기본 개념을 좀 더 잘 이해해 보겠습니다.
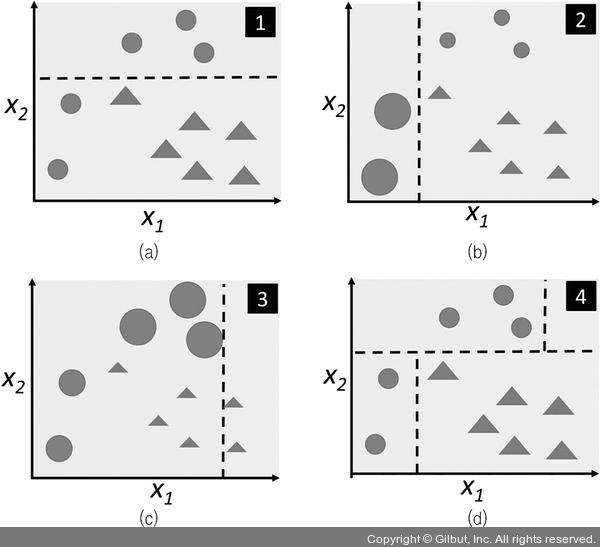
▲ 그림 7-9 에이다부스트
18 Bias, variance, and arcing classifiers, L. Breiman, 1996
19 An improvement of AdaBoost to avoid overfitting, G. Raetsch, T. Onoda, and K. R. Mueller, Proceedings of the International Conference on Neural Information Processing, CiteSeer, 1998
20 역주 사이킷런의 에이다부스트 구현은 기본적으로 부트스트랩 샘플링을 사용합니다.