이 에이다부스트 예시를 하나씩 따라가 보죠. 그림 7- 9(a)는 이진 분류를 위한 훈련 데이터셋을 보여 줍니다. 여기서 모든 샘플은 동일한 가중치를 가집니다. 이 훈련 데이터셋을 바탕으로 깊이가 1인 결정 트리(파선)를 훈련하여 샘플을 두 개의 클래스(삼각형과 원)로 나눕니다. 물론 가능한 비용 함수(또는 결정 트리 앙상블일 경우 불순도 점수)를 최소화하는 트리를 훈련합니다.
다음 단계(그림 7- 9(b))에서 이전에 잘못 분류된 샘플 두 개(원)에 큰 가중치를 부여합니다. 또 옳게 분류된 샘플의 가중치는 낮춥니다. 다음 결정 트리는 가장 큰 가중치를 가진 훈련 샘플에 더 집중할 것입니다. 아마도 이런 훈련 샘플은 분류하기 어려운 샘플일 것입니다. 그림 7- 9(b)에 있는 약한 학습기는 세 개의 원 모양 샘플을 잘못 분류합니다. 그림 7- 9(c)에서 이 샘플들에 큰 가중치가 부여됩니다.
이 에이다부스트 앙상블이 세 번의 부스팅 단계만 가진다고 가정하면 그림 7- 9(d)에서처럼 서로 다른 가중치가 부여된 훈련 데이터셋에서 훈련된 세 개의 약한 학습기를 다수결 투표 방식으로 합칩니다.
이제 에이다부스트의 기본 개념을 잘 이해했을 것입니다. 의사 코드를 사용하여 자세히 알고리즘을 살펴보죠. 여기서 곱셈 기호(×)는 원소별 곱셈을 말하고 점 기호(·)는 두 벡터 사이의 점곱을 의미합니다.
1. 가중치 벡터 w를 동일한 가중치로 설정합니다. 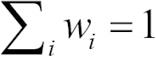
2. m번 부스팅 반복의 j번째에서 다음을 수행합니다.
a. 가중치가 부여된 약한 학습기를 훈련합니다. 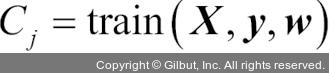
b. 클래스 레이블을 예측합니다. 
c. 가중치가 적용된 에러율을 계산합니다. 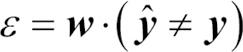
d. 학습기 가중치를 계산합니다. 
e. 가중치를 업데이트합니다. 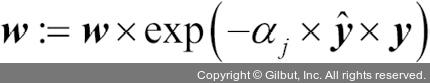
f. 합이 1이 되도록 가중치를 정규화합니다. 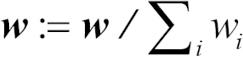
3. 최종 예측을 계산합니다. 
단계 2-c에서 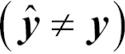 표현은 1 또는 0으로 구성된 이진 벡터를 의미합니다. 예측이 잘못되면 1이고 그렇지 않으면 0입니다.
표현은 1 또는 0으로 구성된 이진 벡터를 의미합니다. 예측이 잘못되면 1이고 그렇지 않으면 0입니다.