에이다부스트 알고리즘이 간단해 보이지만, 그림 7-10의 표와 같이 열 개의 훈련 샘플로 구성된 훈련 데이터셋을 사용하여 구체적인 예제를 살펴보겠습니다.
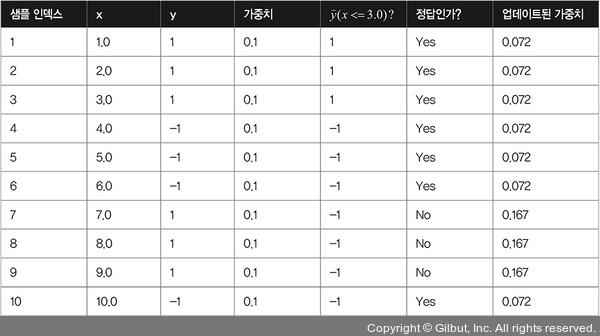
▲ 그림 7-10 열 개의 훈련 샘플로 구성된 훈련 데이터셋
이 표의 첫 번째 열은 1에서 10까지 훈련 샘플의 인덱스를 나타냅니다. 두 번째 열에 각 샘플의 특성 값이 있습니다. 이 데이터는 1차원 데이터셋입니다. 세 번째 열은 각 훈련 샘플 xi에 대한 진짜 클래스 레이블 yi입니다. 여기서 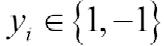 입니다. 네 번째 열은 초기 가중치를 보여 줍니다. 초기에 가중치를 동일하게 초기화합니다(같은 상수 값을 할당합니다). 그다음 합이 1이 되도록 정규화합니다. 샘플이 열 개인 훈련 데이터셋에서는 가중치 벡터 w에 있는 각 가중치 wi를 0.1로 할당 합니다. 예측 클래스 레이블
입니다. 네 번째 열은 초기 가중치를 보여 줍니다. 초기에 가중치를 동일하게 초기화합니다(같은 상수 값을 할당합니다). 그다음 합이 1이 되도록 정규화합니다. 샘플이 열 개인 훈련 데이터셋에서는 가중치 벡터 w에 있는 각 가중치 wi를 0.1로 할당 합니다. 예측 클래스 레이블 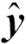 는 다섯 번째 열에 나와 있습니다. 분할 기준은
는 다섯 번째 열에 나와 있습니다. 분할 기준은 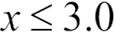 이라고 가정합니다. 표의 마지막 열은 의사 코드에서 정의한 업데이트 규칙에 의해 업데이트된 가중치를 보여 줍니다.
이라고 가정합니다. 표의 마지막 열은 의사 코드에서 정의한 업데이트 규칙에 의해 업데이트된 가중치를 보여 줍니다.