Note ≡ 그레이디언트 부스팅
인기가 많은 또다른 부스팅 알고리즘으로는 그레이디언트 부스팅(gradient boosting)이 있습니다. 에이다부스트와 그레이디언트 부스팅은 전반적인 개념이 같습니다. (깊이가 1인 결정 트리 같은) 약한 학습기를 부스팅하여 강력한 모델을 만듭니다. 에이다부스트와 그레이디언트 부스팅 방식에서 크게 다른 점은 가중치를 업데이트하는 방법과 (약한) 학습기를 연결하는 방법입니다. 그레이디언트 기반 최적화에 익숙하고 그레이디언트 부스팅에 대해 관심이 있다면 제롬 프리드먼(Jerome Friedman)의 논문26을 참고해 보세요. 원본 그레이디언트 부스팅의 계산 효율성을 높인 XGBoost의 논문27도 추천합니다. 사이킷런의 GradientBoostingClassifier 클래스에 이어 사이킷런 0.21 버전에서 XGBoost보다도 빠른 그레이디언트 부스팅 구현인 HistGradientBoostingClassifier가 추가되었습니다. GradientBoostingClassifier와 HistGradientBoostingClassifier에 대한 자세한 내용은 사이킷런 문서28를 참고하세요. 또한, 그레이디언트 부스팅에 대한 간단하고 개괄적인 설명은 제 강의 노트29를 참고할 수 있습니다.
Note ≡
역주 그레이디언트 부스팅은 에이다부스트와는 달리 이전의 약한 학습기가 만든 잔차 오차(residual error)에 대해 학습하는 새로운 학습기를 추가합니다. 신경망 알고리즘이 잘 맞는 이미지, 텍스트 같은 데이터를 제외하고 구조적인 데이터셋에서 현재 가장 높은 성능을 내는 알고리즘 중 하나입니다. 사이킷런에는 GradientBoostingClassifier와 GradientBoostingRegressor 클래스로 구현되어 있습니다. 본문에서 사용한 훈련 데이터를 이용하여 그레이디언트 부스팅 모델을 훈련시켜 보죠.
>>> from sklearn.ensemble import GradientBoostingClassifier
>>> gbrt = GradientBoostingClassifier(n_estimators=20, random_state=42)
>>> gbrt.fit(X_train, y_train)
>>> gbrt_train_score = gbrt.score(X_train, y_train)
>>> gbrt_test_score = gbrt.score(X_test, y_test)
>>> print('그레이디언트 부스팅의 훈련 정확도/테스트 정확도 %.3f/%.3f'
... % (gbrt_train_score, gbrt_test_score))
그레이디언트 부스팅의 훈련 정확도/테스트 정확도 1.000/0.917
20개의 트리를 사용하여 에이다부스트 모델과 동일한 성능을 냈습니다. 여기서는 그레이디언트 부스팅의 결정 경계가 배깅의 결정 경계와 유사합니다.
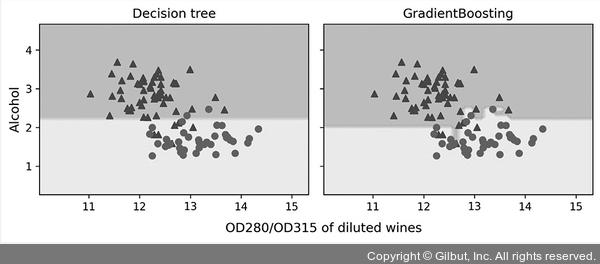
▲ 그림 7-12 결정 트리와 그레이디언트 부스팅의 결정 경계
그레이디언트 부스팅에서 중요한 매개변수 중 하나는 각 트리가 오차에 기여하는 정도를 조절하는 learning_rate입니다. learning_rate가 작으면 성능은 높아지지만 많은 트리가 필요합니다. 이 매개변수의 기본값은 0.1입니다.
그레이디언트 부스팅이 사용하는 손실 함수는 loss 매개변수에서 지정합니다. GradientBoostingClassifier일 경우 로지스틱 회귀를 의미하는 'deviance', GradientBoostingRegressor일 경우 최소 제곱을 의미하는 'ls'가 기본값입니다.
그레이디언트 부스팅이 오차를 학습하기 위해 사용하는 학습기는 DecisionTreeRegressor입니다. Decision TreeRegressor의 불순도 조건은 'mse', 'mae' 등입니다. 따라서 그레이디언트 부스팅의 criterion 매개변수도 DecisionTreeRegressor의 불순도 조건을 따라서 'mse', 'mae', 그리고 제롬 프리드먼이 제안한 MSE 버전인 'friedman_mse'(기본값)를 사용합니다. 하지만 'mae'일 경우 그레이디언트 부스팅의 결과가 좋지 않기 때문에 이 옵션은 사이킷런 0.24 버전부터 경고가 발생하고 사이킷런 0.26 버전에서 삭제될 예정입니다.
subsample 매개변수를 기본값 1.0보다 작은 값으로 지정하면 훈련 데이터셋에서 subsample 매개변수에 지정된 비율만큼 랜덤하게 샘플링하여 트리를 훈련합니다. 이를 확률적 그레이디언트 부스팅이라고 부릅니다. 이는 랜덤 포레스트나 에이다부스트의 부트스트랩 샘플링과 비슷하게 과대적합을 줄이는 효과를 냅니다. 또한, 남은 샘플을 사용하여 OOB 점수를 계산할 수 있습니다. subsample 매개변수가 1.0보다 작을 때 그레이디언트 부스팅 객체의 oob_improvement_ 속성에 이전 트리의 OOB 손실 값에서 현재 트리의 OOB 손실을 뺀 값이 기록되어 있습니다. 이 값에 음수를 취해서 누적하면 트리가 추가되면서 과대적합되는 지점을 찾을 수 있습니다.
>>> gbrt = GradientBoostingClassifier(n_estimators=100,
... subsample=0.5,
... random_state=1)
>>> gbrt.fit(X_train, y_train)
>>> oob_loss = np.cumsum(-gbrt.oob_improvement_)
>>> plt.plot(range(100), oob_loss)
>>> plt.xlabel('number of trees')
>>> plt.ylabel('loss')
>>> plt.show()
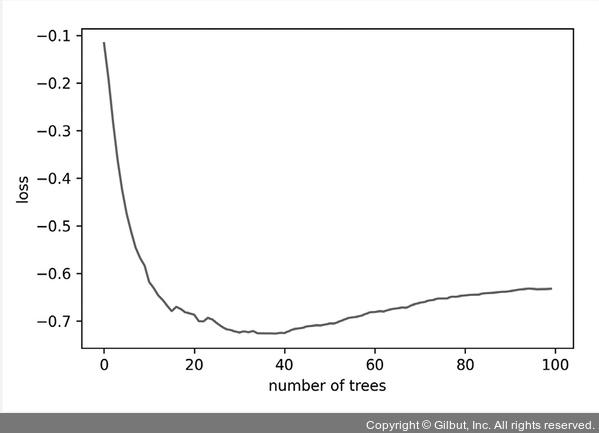
▲ 그림 7-13 그레이디언트 부스팅의 OOB 손실
사이킷런 0.20 버전부터는 그레이디언트 부스팅에 조기 종료(early stopping) 기능을 지원하기 위한 매개변수 n_iter_no_change, validation_fraction, tol이 추가되었습니다. 훈련 데이터에서 validation_fraction 비율(기본값 0.1)만큼 떼어 내어 측정한 손실이 n_iter_no_change 반복 동안에 tol 값(기본값 1e-4) 이상 향상되지 않으면 훈련이 멈춥니다.
히스토그램 기반 부스팅은 입력 특성을 256개의 구간으로 나누어 노드를 분할에 사용합니다. 일반적으로 샘플 개수가 1만 개보다 많은 경우 그레이디언트 부스팅보다 히스토그램 기반 부스팅이 훨씬 빠릅니다. 앞에서와 같은 데이터를 HistGradientBoostingClassifier에 적용해 보겠습니다. 이 클래스는 아직 실험적이기 때문에 사용하기 전에 먼저 활성화해야 합니다.
>>> from sklearn.experimental import enable_hist_gradient_boosting
>>> from sklearn.ensemble import HistGradientBoostingClassifier
>>> hgbc = HistGradientBoostingClassifier(random_state=1)
>>> hgbc.fit(X_train, y_train)
>>> hgbc_train_score = gbrt.score(X_train, y_train)
>>> hgbc_test_score = gbrt.score(X_test, y_test)
>>> print('그 레이디언트 부스팅 훈련 정확도/테스트 정확도 %.3f/%.3f'
... % (hgbc_train_score, hgbc_test_score))
그레이디언트 부스팅 훈련 정확도/테스트 정확도 1.000/0.917
사이킷런 0.24 버전부터 HistGradientBoostingClassifier와 HistGradientBoostingRegressor에서 범주형 특성을 그대로 사용할 수 있습니다. categorical_features 매개변수에 불리언 배열이나 정수 인덱스 배열을 전달하여 범주형 특성을 알려 주어야 합니다.
XGBoost(https://xgboost.ai/)에서도 tree_method 매개변수를 'hist'로 지정하여 히스토그램 기반 부스팅을 사용할 수 있습니다. 다음 명령으로 xgboost를 설치합니다.
> pip install xgboost
코랩에는 이미 XGBoost 라이브러리가 설치되어 있으므로 간단히 테스트해 볼 수 있습니다.
>>> from xgboost import XGBClassifier
>>> xgb = XGBClassifier(tree_method='hist', random_state=1)
>>> xgb.fit(X_train, y_train)
>>> xgb_train_score = xgb.score(X_train, y_train)
>>> xgb_test_score = xgb.score(X_test, y_test)
>>> print('XGBoost 훈련 정확도/테스트 정확도 %.3f/%.3f'
... % (xgb_train_score, xgb_test_score))
XGBoost 훈련 정확도/테스트 정확도 0.979/0.917
또 다른 인기 높은 히스토그램 기반 부스팅 알고리즘은 마이크로소프트에서 만든 LightGBM(https://lightgbm.readthedocs.io/)입니다. 사실 사이킷런의 히스토그램 기반 부스팅은 LightGBM에서 영향을 많이 받았습니다. 다음 명령으로 lightgbm을 설치합니다.
> pip install lightgbm
LightGBM도 코랩에 설치되어 있으므로 바로 테스트해 볼 수 있습니다.
>>> from lightgbm import LGBMClassifier
>>> lgb = LGBMClassifier(random_state=1)
>>> lgb.fit(X_train, y_train)
>>> lgb_train_score = lgb.score(X_train, y_train)
>>> lgb_test_score = lgb.score(X_test, y_test)
>>> print('LightGBM 훈련 정확도/테스트 정확도 %.3f/%.3f'
... % (lgb_train_score, lgb_test_score))
LightGBM 훈련 정확도/테스트 정확도 0.979/0.917
26 Greedy function approximation: a gradient boosting machine. Jerome Friedman. Annals of Statistics 2001, pp. 1189-1232
27 XGBoost: A scalable tree boosting system. Tianqi Chen and Carlos Guestrin. Proceeding of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM 2016, pp. 785-794