맨 처음 접근 방법은 클라이언트가 오로지 서비스 디스커버리 엔진에만 완전히 의존하여 서비스를 호출할 때마다 서비스 위치를 확인하는 것이다. 이 방법을 사용하면 서비스 디스커버리 엔진은 등록된 마이크로서비스 인스턴스를 호출할 때마다 호출된다. 불행히도 이것은 서비스 클라이언트가 서비스를 찾고 호출하는 데 서비스 디스커버리 엔진에 완전히 의존하기 때문에 취약한 방법이다.
더욱 견고한 접근 방법은 클라이언트 측 로드 밸런싱(client-side load balancing)으로 알려진 방법을 사용하는 것이다. 이 메커니즘은 존(zone)별 또는 라운드 로빈(round robin) 같은 알고리즘을 사용하여 호출할 서비스의 인스턴스를 호출한다. ‘라운드 로빈 알고리즘식 로드 밸런싱’을 이야기할 때 우리는 클라이언트 요청을 여러 서버에 분산시키는 방법을 의미한다. 이 방법은 클라이언트 요청을 차례로 각 서버에 전달하는 것이다. 유레카(Eureka)와 함께 클라이언트 측 로드 밸런싱을 사용하는 장점은 서비스 인스턴스가 다운되면, 인스턴스가 레지스트리에서 제거된다는 것이다. 이 작업이 완료되면 클라이언트 측 로드 밸런서는 레지스트리 서비스와 지속적으로 통신하여 자동으로 레지스트리를 업데이트한다. 그림 6-3에서 이 방법을 보여 준다.
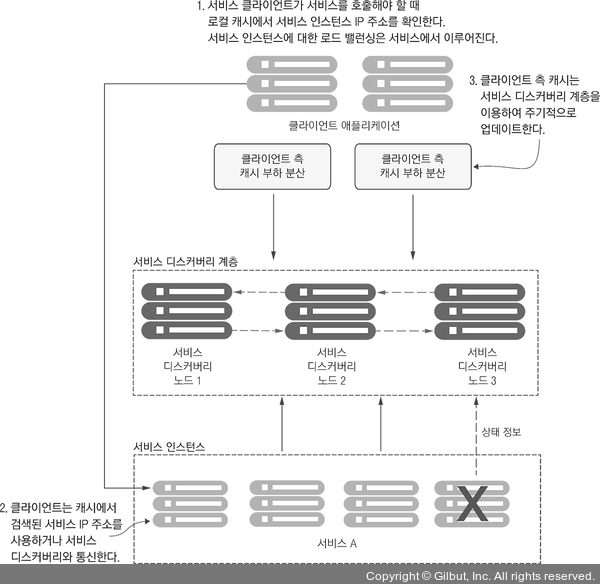
▲ 그림 6-3 클라이언트 측 로드 밸런싱은 서비스 위치를 캐싱하므로 서비스 클라이언트가 매 호출마다 서비스 디스커버리에 물어보지 않아도 된다