1.2.2 강화 학습으로 반응형 문제 해결
강화 학습은 머신 러닝의 또 다른 종류입니다. 강화 학습은 환경과 상호 작용하여 시스템(에이전트(agent)) 성능을 향상하는 것이 목적입니다. 환경의 현재 상태 정보는 보상(reward) 신호를 포함하기 때문에 강화 학습을 지도 학습과 관련된 분야로 생각할 수 있습니다. 강화 학습의 피드백은 정답(ground truth) 레이블이나 값이 아닙니다. 보상 함수로 얼마나 행동이 좋은지를 측정한 값입니다. 에이전트는 환경과 상호 작용하여 보상이 최대화되는 일련의 행동을 강화 학습으로 학습합니다. 탐험적인 시행착오(trial and error) 방식이나 신중하게 세운 계획을 사용합니다.
강화 학습의 대표적인 예는 체스 게임입니다. 에이전트는 체스판의 상태(환경)에 따라 기물의 이동을 결정합니다. 보상은 게임을 종료했을 때 승리하거나 패배하는 것으로 정의할 수 있습니다.
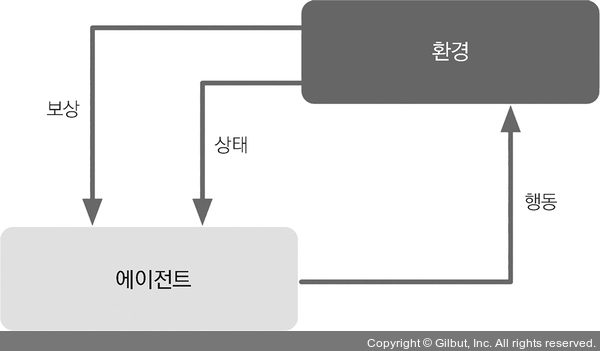
▲ 그림 1-5 강화 학습