3.3.2 로지스틱 손실 함수의 가중치 학습
로지스틱 회귀 모델이 확률과 클래스 레이블을 어떻게 예측하는지 배웠습니다. 이제 모델 파라미터인 가중치 w와 절편 유닛 b를 어떻게 학습하는지 간단하게 살펴보겠습니다. 이전 장에서 다음과 같은 평균 제곱 오차 손실 함수를 정의했습니다.
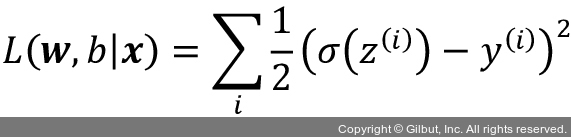
아달린 분류 모델에서 이 함수를 최소화하는 파라미터를 학습합니다. 로지스틱 회귀의 손실 함수를 유도하는 방법을 설명하기 위해 먼저 로지스틱 회귀 모델을 만들 때 최대화하려는 가능도(likelihood) L을 정의하겠습니다. 데이터셋에 있는 각 샘플이 서로 독립적이라고 가정합니다. 공식은 다음과 같습니다.10
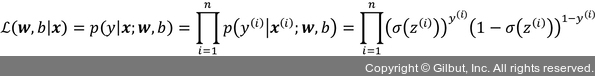
실전에서는 이 공식의 (자연) 로그를 최대화하는 것이 더 쉽습니다. 이 함수를 로그 가능도 함수라고 합니다.
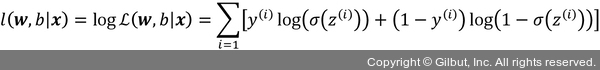
첫째, 로그 함수를 적용하면 가능도가 매우 작을 때 일어나는 수치상의 언더플로(underflow)를 미연에 방지합니다. 둘째, 계수의 곱을 계수의 합으로 바꿀 수 있습니다. 미적분을 기억하고 있을지 모르지만 이렇게 하면 도함수를 구하기 쉽습니다.