사이킷런의 RandomForestClassifier를 포함하여 대부분의 라이브러리에서는 부트스트랩 샘플 크기를 원본 훈련 데이터셋의 샘플 개수와 동일하게 합니다.24 보통 이렇게 하면 균형 잡힌 편향 -분산 트레이드오프를 얻습니다. 분할에 사용할 특성 개수 d는 훈련 데이터셋에 있는 전체 특성 개수보다 작게 지정하는 편입니다. 사이킷런과 다른 라이브러리에서 사용하는 적당한 기본값은 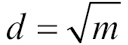 입니다.25 여기에서 m은 훈련 데이터셋에 있는 특성 개수입니다.
입니다.25 여기에서 m은 훈련 데이터셋에 있는 특성 개수입니다.
사이킷런에 이미 준비되어 있기 때문에 직접 개별 결정 트리를 만들어 랜덤 포레스트 분류기를 구성할 필요가 없습니다.
>>> from sklearn.ensemble import RandomForestClassifier
>>> forest = RandomForestClassifier(n_estimators=25,
... random_state=1,
... n_jobs=2)
>>> forest.fit(X_train, y_train)
>>> plot_decision_regions(X_combined, y_combined,
... classifier=forest, test_idx=range(105,150))
>>> plt.xlabel('Petal length [cm]')
>>> plt.ylabel('Petal width [cm]')
>>> plt.legend(loc='upper left')
>>> plt.tight_layout()
>>> plt.show()