그림 4-9에서 볼 수 있듯이 특성 개수가 줄었을 때 검증 데이터셋에서 KNN 분류기의 정확도가 향상되었습니다. 3장 KNN 알고리즘에서 설명했던 차원의 저주가 감소하기 때문입니다. 또 k = {3, 7, 8, 9, 10, 11, 12}에서 분류기가 100% 정확도를 달성한 것을 볼 수 있습니다.
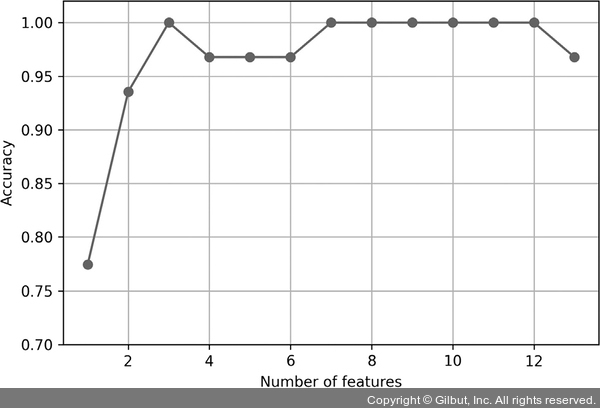
▲ 그림 4-9 특성 개수가 모델 정확도에 미치는 영향
궁금하니 가장 작은 개수의 조합(k = 3)에서 높은 검증 데이터셋 성능을 내는 특성이 어떤 것인지 확인해 보죠.
>>> k3 = list(sbs.subsets_[10])
>>> print(df_wine.columns[1:][k3])
Index(['Alcohol', 'Malic acid', 'OD280/OD315 of diluted wines'], dtype='object')