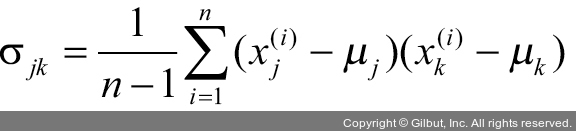그다음 Wine 데이터셋을 70%와 30% 비율로 훈련 데이터셋과 테스트 데이터셋으로 나누고 표준화를 적용하여 단위 분산을 갖도록 합니다.
>>> from sklearn.model_selection import train_test_split
>>> X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
>>> X_train, X_test, y_train, y_test = \
>>> train_test_split(X, y, test_size=0.3,
... stratify=y,
... random_state=0)
>>> # 특성을 표준화 전처리합니다
>>> from sklearn.preprocessing import StandardScaler
>>> sc = StandardScaler()
>>> X_train_std = sc.fit_transform(X_train)
>>> X_test_std = sc.transform(X_test)
앞 코드를 실행하여 필수적인 전처리 단계를 완료한 후 공분산 행렬을 만드는 두 번째 단계를 진행합니다. 공분산 행렬은 d×d 차원의 대칭 행렬로 특성 상호 간의 공분산을 저장합니다. d는 데이터셋에 있는 차원 개수입니다. 예를 들어 전체 샘플에 대한 두 특성 Aj와 xk 사이의 공분산은 다음 식으로 계산할 수 있습니다.