>>> tot = sum(eigen_vals.real)
>>> discr = [(i / tot) for i in sorted(eigen_vals.real,
... reverse=True)]
>>> cum_discr = np.cumsum(discr)
>>> plt.bar(range(1, 14), discr, align='center',
... label='Individual discriminability')
>>> plt.step(range(1, 14), cum_discr, where='mid',
... label='Cumulative discriminability')
>>> plt.ylabel('Discriminability ratio')
>>> plt.xlabel('Linear Discriminants')
>>> plt.ylim([-0.1, 1.1])
>>> plt.legend(loc='best')
>>> plt.tight_layout()
>>> plt.show()
결과 그래프에서 볼 수 있듯이 처음 두 개의 선형 판별 벡터가 Wine 데이터셋에 있는 정보 중 거의 100%를 잡아냅니다.
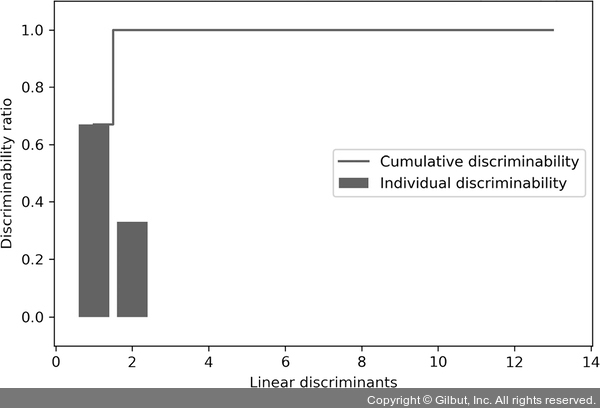
▲ 그림 5-9 유용한 정보 100%를 잡아내는 두 개의 판별 벡터