Note ≡
역주 이전 절에서 단계별로 설명한 LDA 구현은 LinearDiscriminantAnalysis 클래스의 solver 매개변수가 'eigen'일 때입니다. 실제 사이킷런의 LDA 구현은 책과는 조금 다릅니다.
전체 평균과 클래스별 평균 사이의 관계는 다음과 같습니다.
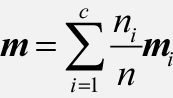
이를 클래스 내 산포 행렬 Sw에 적용하고 클래스별 산포 행렬 Si를 클래스별 공분산 행렬 ∑i로 정의하면 다음과 같이 쓸 수 있습니다.
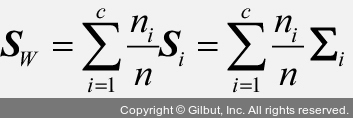
먼저 클래스 비율을 계산하고 그다음 클래스 내 산포 행렬 Sw를 계산해 보죠.
>>> y_uniq, y_count = np.unique(y_train, return_counts=True)
>>> priors = y_count / X_train_std.shape[0]
>>> priors
array([0.3306, 0.4032, 0.2661])
>>> s_w = np.zeros((X_train_std.shape[1], X_train_std.shape[1]))
>>> for i, label in enumerate(y_uniq):
>>> s_w += priors[i] * np.cov(X_train_std[y_train==label].T, bias: True)