앞 코드에서 np.cov() 함수를 사용할 때 bias 매개변수를 True로 지정했습니다. 기본적으로 np.cov() 함수는 공분산 행렬을 계산할 때 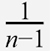 을 곱합니다. 사이킷런 구현을 따라 bias = True로 설정하면
을 곱합니다. 사이킷런 구현을 따라 bias = True로 설정하면 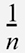 을 곱하도록 바꿀 수 있습니다.
을 곱하도록 바꿀 수 있습니다.
클래스 간의 산포 행렬도 클래스 비율을 곱해 계산합니다.
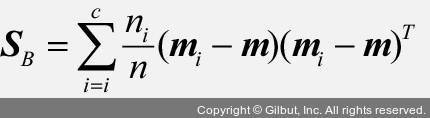
s_b = np.zeros((X_train_std.shape[1], X_train_std.shape[1]))
for i, mean_vec in enumerate(mean_vecs):
n = X_train_std[y_train == i + 1].shape[0]
mean_vec = mean_vec.reshape(-1, 1)
s_b += priors[i] * (mean_vec - mean_overall).dot((mean_vec - mean_overall).T)
SW-1SB를 직접 구해 고윳값 분해를 하는 대신 scipy.linalg.eigh 함수에 SB와 SW를 전달하면 SBw = λSWw 식의 고윳값을 바로 계산할 수 있습니다. 계산 후에 고윳값 크기의 역순으로 고유 벡터를 정렬하여 최종 고유 벡터를 구합니다.
import scipy
ei_val, ei_vec = scipy.linalg.eigh(s_b, s_w)
ei_vec = ei_vec[:, np.argsort(ei_val)[::-1]]