6.3.1 학습 곡선으로 편향과 분산 문제 분석
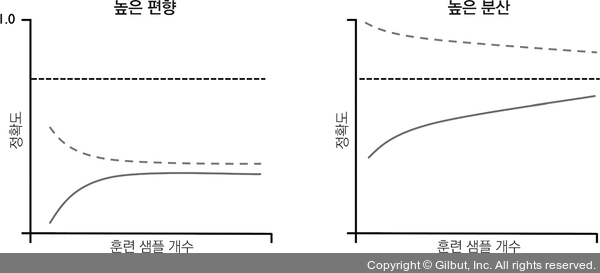
주어진 훈련 데이터셋에 비해 모델이 너무 복잡하면, 예를 들어 매우 깊은 결정 트리 같은 경우 모델이 훈련 데이터에 과대적합되고 처음 본 데이터에 잘 일반화되지 못하는 경향이 있습니다. 보통 훈련 샘플을 더 모으면 과대적합을 줄이는 데 도움이 됩니다.
하지만 실전에서는 데이터를 더 모으는 것이 매우 비싸거나 그냥 불가능할 때도 많습니다. 모델의 훈련 정확도와 검증 정확도를 훈련 데이터셋의 크기 함수로 그래프를 그려 보면 모델에 높은 분산의 문제가 있는지 높은 편향의 문제가 있는지 쉽게 감지할 수 있습니다. 더 많은 데이터를 모으는 것이 문제를 해결할 수 있을지 판단이 가능해집니다.
사이킷런으로 학습 곡선을 그리는 방법을 보기 전에 그림 6-5에서 두 종류의 문제에 대해 논의해 보죠.