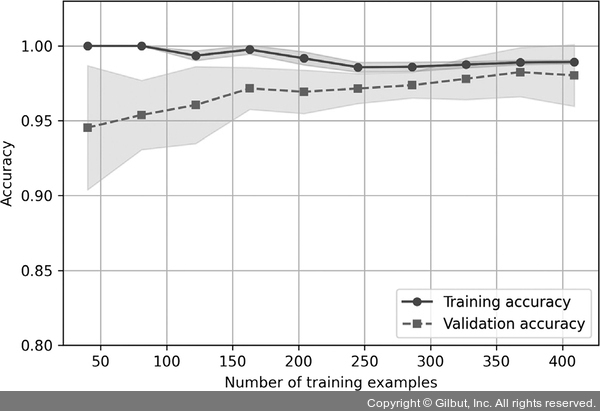
▲ 그림 6-6 훈련 샘플 개수에 따라 훈련 세트와 검증 세트의 정확도를 보여 주는 학습 곡선
learning_curve 함수의 train_sizes 매개변수를 통해 학습 곡선을 생성하는 데 사용할 훈련 샘플의 개수나 비율을 지정할 수 있습니다. 여기에서는 train_sizes = np.linspace(0.1, 1.0, 10)으로 지정해서 일정한 간격으로 훈련 데이터셋의 비율 열 개를 설정했습니다. 기본적으로 learning_curve 함수는 계층별 k-겹 교차 검증을 사용하여 분류기의 교차 검증 정확도를 계산합니다. cv 매개변수를 통해 k 값을 10으로 지정했기 때문에 계층별 10-겹 교차 검증을 사용합니다.