close
더북(TheBook)
search
머신 러닝 교과서: 파이토치 편
더북(TheBook)
home
Home
1장 컴퓨터는 데이터에서 배운다
1.1 데이터를 지식으로 바꾸는 지능적인 시스템 구축
1.2 머신 러닝의 세 가지 종류
1.2.1 지도 학습으로 미래 예측
1.2.2 강화 학습으로 반응형 문제 해결
1.2.3 비지도 학습으로 숨겨진 구조 발견
1.3 기본 용어와 표기법 소개
1.3.1 이 책에서 사용하는 표기법과 규칙
1.3.2 머신 러닝 용어
1.4 머신 러닝 시스템 구축 로드맵
1.4.1 전처리: 데이터 형태 갖추기
1.4.2 예측 모델 훈련과 선택
1.4.3 모델을 평가하고 본 적 없는 샘플로 예측
1.5 머신 러닝을 위한 파이썬
1.5.1 파이썬과 PIP에서 패키지 설치
1.5.2 아나콘다 파이썬 배포판과 패키지 관리자 사용
1.5.3 과학 컴퓨팅, 데이터 과학, 머신 러닝을 위한 패키지
1.6 요약
2장 간단한 분류 알고리즘 훈련
2.1 인공 뉴런: 초기 머신 러닝의 간단한 역사
2.1.1 인공 뉴런의 수학적 정의
2.1.2 퍼셉트론 학습 규칙
2.2 파이썬으로 퍼셉트론 학습 알고리즘 구현
2.2.1 객체 지향 퍼셉트론 API
2.2.2 붓꽃 데이터셋에서 퍼셉트론 훈련
2.3 적응형 선형 뉴런과 학습의 수렴
2.3.1 경사 하강법으로 손실 함수 최소화
2.3.2 파이썬으로 아달린 구현
2.3.3 특성 스케일을 조정하여 경사 하강법 결과 향상
2.3.4 대규모 머신 러닝과 확률적 경사 하강법
2.4 요약
3장 사이킷런을 타고 떠나는 머신 러닝 분류 모델 투어
3.1 분류 알고리즘 선택
3.2 사이킷런 첫걸음: 퍼셉트론 훈련
3.3 로지스틱 회귀를 사용한 클래스 확률 모델링
3.3.1 로지스틱 회귀의 이해와 조건부 확률
3.3.2 로지스틱 손실 함수의 가중치 학습
3.3.3 아달린 구현을 로지스틱 회귀 알고리즘으로 변경
3.3.4 사이킷런을 사용하여 로지스틱 회귀 모델 훈련
3.3.5 규제를 사용하여 과대적합 피하기
3.4 서포트 벡터 머신을 사용한 최대 마진 분류
3.4.1 최대 마진
3.4.2 슬랙 변수를 사용하여 비선형 분류 문제 다루기
3.4.3 사이킷런의 다른 구현
3.5 커널 SVM을 사용하여 비선형 문제 풀기
3.5.1 선형적으로 구분되지 않는 데이터를 위한 커널 방법
3.5.2 커널 기법을 사용하여 고차원 공간에서 분할 초평면 찾기
3.6 결정 트리 학습
3.6.1 정보 이득 최대화: 자원을 최대로 활용
3.6.2 결정 트리 만들기
3.6.3 랜덤 포레스트로 여러 개의 결정 트리 연결
3.7 k-최근접 이웃: 게으른 학습 알고리즘
3.8 요약
4장 좋은 훈련 데이터셋 만들기: 데이터 전처리
4.1 누락된 데이터 다루기
4.1.1 테이블 형태 데이터에서 누락된 값 식별
4.1.2 누락된 값이 있는 훈련 샘플이나 특성 제외
4.1.4 사이킷런 추정기 API 익히기
4.2 범주형 데이터 다루기
4.2.1 판다스를 사용한 범주형 데이터 인코딩
4.2.2 순서가 있는 특성 매핑
4.2.3 클래스 레이블 인코딩
4.2.4 순서가 없는 특성에 원-핫 인코딩 적용
4.3 데이터셋을 훈련 데이터셋과 테스트 데이터셋으로 나누기
4.4 특성 스케일 맞추기
4.5 유용한 특성 선택
4.5.1 모델 복잡도 제한을 위한 L1 규제와 L 2 규제
4.5.2 L 2 규제의 기하학적 해석
4.5.3 L1 규제를 사용한 희소성
4.5.4 순차 특성 선택 알고리즘
4.6 랜덤 포레스트의 특성 중요도 사용
4.7 요약
5장 차원 축소를 사용한 데이터 압축
5.1 주성분 분석을 통한 비지도 차원 축소
5.1.1 주성분 분석의 주요 단계
5.1.2 주성분 추출 단계
5.1.3 총 분산과 설명된 분산
5.1.4 특성 변환
5.1.5 사이킷런의 주성분 분석
5.2 선형 판별 분석을 통한 지도 방식의 데이터 압축
5.2.1 주성분 분석 vs 선형 판별 분석
5.2.2 선형 판별 분석의 내부 동작 방식
5.2.3 산포 행렬 계산
5.2.4 새로운 특성 부분 공간을 위해 선형 판별 벡터 선택
5.2.5 새로운 특성 공간으로 샘플 투영
5.2.6 사이킷런의 LDA
5.3 비선형 차원 축소와 시각화
5.3.1 비선형 차원 축소를 고려하는 이유는 무엇인가요?
5.3.2 t-SNE를 사용한 데이터 시각화
5.4 요약
6장 모델 평가와 하이퍼파라미터 튜닝의 모범 사례
6.1 파이프라인을 사용한 효율적인 워크플로
6.1.1 위스콘신 유방암 데이터셋
6.1.2 파이프라인으로 변환기와 추정기 연결
6.2 k-겹 교차 검증을 사용한 모델 성능 평가
6.2.1 홀드아웃 방법
6.2.2 k-겹 교차 검증
6.3 학습 곡선과 검증 곡선을 사용한 알고리즘 디버깅
6.3.1 학습 곡선으로 편향과 분산 문제 분석
6.3.2 검증 곡선으로 과대적합과 과소적합 조사
6.4 그리드 서치를 사용한 머신 러닝 모델 세부 튜닝
6.4.1 그리드 서치를 사용한 하이퍼파라미터 튜닝
6.4.2 랜덤 서치로 하이퍼파라미터 설정을 더 넓게 탐색하기
6.4.3 SH 방식을 사용한 자원 효율적인 하이퍼파라미터 탐색
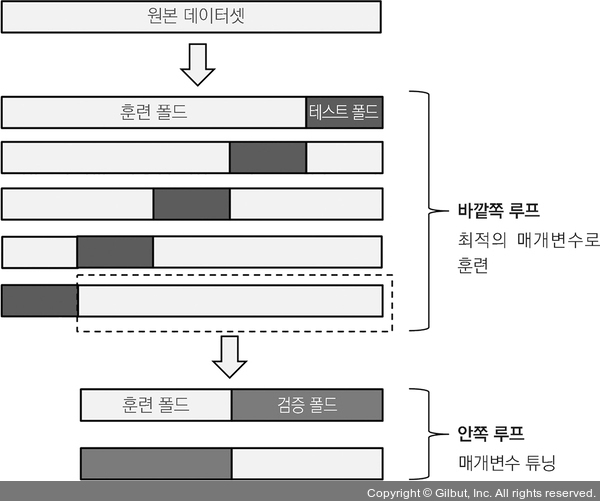
6.4.4 중첩 교차 검증을 사용한 알고리즘 선택
6.5 여러 가지 성능 평가 지표
6.5.1 오차 행렬
6.5.2 분류 모델의 정밀도와 재현율 최적화
6.5.3 ROC 곡선 그리기
6.5.5 불균형한 클래스 다루기
6.6 요약
▲ 그림 6-10
중첩 교차 검증
사이킷런에서는 다음과 같이 그리드 서치를 사용한 중첩 교차 검증을 수행할 수 있습니다.
다음으로 공부할 책 추천
Prev
BUY
Next
신간 소식 구독하기
뉴스레터에 가입하시고 이메일로 신간 소식을 받아 보세요.
Email address